Brane: A Specification
This book is still in development. Everything is currently subject to change.
This book documents the workings of the Brane framework, so it may be maintained easily by future parties or further the understanding of users who want to know exactly what they are working with. Note, however, that this book is not a code documentation, nor is it a user guide; we solely focus on its design. It can be thought of as a kind of (informal) specification of a Brane framework.
For a how to work with the framework, please check the Brane: The User Guide book: it describes how to work with Brane for all four of the framework's target roles (system engineers, policy experts, software engineers and scientists).
Code documentation is provided by the Rust automated documentation generation (cargo doc). A version generated for BRANE 2.0.0 on x86-64 machines can be found hosted here. For other versions or platforms, check the the source code itself.
To start, first head over to the Overview page, which talks about Brane in general and how this book will look like. From there, you can select topics that are most of interest.
Attribution
The icons used in this book (![]() ,
, ![]() ,
, ![]() ) are provided by Flaticon.
) are provided by Flaticon.
Overview of the Brane framework
The Brane framework is an infrastructure designed to facilitate computing over multiple compute sites, in a site-agnostic way. It thus acts as a middleware between a workflow that a scientist wants to run and various compute facilities with different capabilities, hardware and software.
Although originally developed as a general purpose workflow execution system, it has recently been adopted for use in healthcare as part of the Enabling Personalized Interventions (EPI) project. To this end, the framework is being adapted and redesigned with a focus on working with sensitive datasets owned by different domains, and keeping the datasets in control of the data.
Brane is federated, which means that is has a centralised part that acts as an orchestrator that mediates work between decentralised parts that are hosted on participating domains. As such, they are called the orchestrator and a domain, respectively.
The reason that Brane is called a framework is that domains are free to implement their part of the framework as they wish, as long as they adhere to the overall framework interface. Moreover, different Brane instances (i.e., a particular orchestrator with a particular set of domains) can have different implementations, too, allowing it to be tailored to a particular use case's needs.
Book layout
We cover a number of different aspects of Brane's design in this book, separated into different groups of chapters.
First, in the development-chapters, we detail how to setup your laptop such that you can develop Brane. Part of this is compiling the most recent version of the framework.
In design requirements, we will discuss the design behind Brane and what motivated decisions made. Here, we will layout the parculiarities of Brane's use case and which assumptions where made. This will help to contextualise the more technical discussion later on.
The series on implementation details how the requirements are implemented by discussing notable implementation decisions on a high-level. For low-level implementation, refer to the auto-generated Brane Code Documentation.
In framework specification, we provide some lower-level details on the "specification" parts of the framework. In essence, this will give technical interfaces or APIs that allow components to communicate with each other, even if they have a custom implementation.
Finally, we discuss future work for Brane: ideas not yet implemented but which we believe are essential or otherwise very practical.
In addition to the main story, there is also the Appendix which discusses anything not part of the official story but worth noting. Most notably, the specification of the custom Domain-Specific Language (DSL) of Brane is given here, BraneScript.
Introduction
These chapters detail how to prepare your environment for developing Brane.
The compilation-chapter discusses which dependencies to install, and then what to do, to be able to compile Brane binaries and services.
Next
You can select the specific development chapter above or in the sidebar to the left.
Alternatively, you can switch topics altogether using the same sidebar.
Compiling binaries
This chapter explains how to compile the various Brane components.
First, start by installing the required dependencies.
Then, if you are coming from the scientist- or software engineer-chapters, you are most likely interested in compiling the brane CLI tool.
If you are coming from the administrator-chapters, you are most likely interested in compiling the branectl CLI tool and the various instance images.
People who aim to either run the Brane IDE or automatically compile BraneScript in another fashion, should checkout the section on libbrane_cli and branec.
Dependencies
If you want to compile the framework yourself, you have to install additional dependencies to do so.
Various parts of the framework are compiled differently. Most notably:
- Any binaries (
brane,branectl,branecorlibbrane_cli.so) are compiled using Rust'scargo; and - Any services (i.e., nodes) are compiled within a Docker environment.
Depending on which to install, you may need to install the dependencies for both of them.
Binaries - Rust and Cargo
To compile Rust code natively on your machine, you should install the language toolchain plus any other dependencies required for the project. An overview per supported OS can be found below:
Windows (brane, branec and libbrane_cli.so only)
- Install Rust and its tools using rustup (follow the instructions on the website).
- Install the Visual Studio Tools to install the required Windows compilers. Installing the Build Tools for Visual Studio should be sufficient.
- Install Perl (Strawberry Perl is fine) (follow the instructions on the website).
macOS
- Install Rust and its tools using rustup:
Or, if you want a version that installs the default setup and that does not ask for confirmation:# Same command as suggested by Rustup itself curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | shcurl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh -s -- --profile default -y - Install the Xcode Command-Line Tools, since that contains most of the compilers and other tools we need
# Follow the prompt after this to install it (might take a while) xcode-select --install
The main compilation script,
make.py, is tested for Python 3.7 and higher. If you have an older Python version, you may have to upgrade it first. We recommend using some virtualized environment such as pyenv to avoid breaking your OS or other projects.
Ubuntu / Debian
- Install Rust and its tools using rustup:
Or, if you want a version that installs the default setup and that does not ask for confirmation:# Same command as suggested by Rustup itself curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | shcurl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh -s -- --profile default -y - Install the packages required by Brane's dependencies with
apt:sudo apt-get update && sudo apt-get install -y \ gcc g++ \ cmake
Arch Linux
- Install Rust and its tools using rustup:
Or, if you want a version that installs the default setup and that does not ask for confirmation:# Same command as suggested by Rustup itself curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | shcurl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh -s -- --profile default -y - Install the packages from
pacmanrequired by Brane's dependenciessudo pacman -Syu \ gcc g++ \ cmake
Services - control, worker and proxy nodes
The services are build in Docker. As such, install it on your machine, and it should take care of the rest.
Simply follow the instructions on https://www.docker.com/get-started/ to get started.
Compilation
With the dependencies install, you can then compile the parts of the framework of your choosing.
For all of them, first clone the repository. Either download it from Github's interface (the green button in the top-right), or clone it using the command-line:
git clone https://github.com/epi-project/brane && cd brane
Then you can use the make.py script to install what you like:
- To build the
braneCLI tool, run:python3 make.py cli - To build the
branectlCLI tool, run:python3 make.py ctl - To build the
branecBraneScript compiler, run:python3 make.py cc - To build the
libbrane_cli.sodynamic library, run:python3 make.py libbrane_cli - To build the servives for a control node, run:
python3 make.py instance - To build the servives for a worker node, run:
python3 make.py worker-instance - To build the servives for a proxy node, run:
python3 make.py proxy-instance
Note that compiling any of these will result in quite large build caches (order of GB's). Be sure to have at least 10 GB available on your device before you start compiling to make sure your OS keeps functioning.
For any of the binaries (brane, branectl and branec), you may make them available in your PATH by copying them to some system location, e.g.,
sudo cp ./target/release/brane /usr/local/bin/brane
to make them available system-wide.
Troubleshooting
This section lists some common issues that occur when compiling Brane.
-
I'm running out of space on my machine. What to do?
Both the build caches of Cargo and Docker tend to accumulate a lot of artefacts, most of which aren't used anymore. As such, it can save a lot of space to clear them.For Cargo, simply remove the
target-directory:rm -rf ./targetFor Docker, you can clear the Buildx build cache:
docker buildx prune -af The above command clears all Buildx build cache, not just Brane's. Use with care.It can also sometimes help to prune old images or containers if you're building new versions often.
Do note that running either will re-trigger a new, clean build, and therefore may take some time.
-
Errors like
ERROR: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?orunix:///var/run/docker.sock not foundwhen building services
This means that your Docker engine is most likely not running. On Windows and macOS, start it by starting the Docker Engine application. On Linux, run:sudo systemctl start docker -
Permission deniederrors when building services (Linux)
Running Docker containers may be a security risk because it can be used to edit any file on a system, permission or not. As such, you have to be added to thedocker-group to run it without usingsudo.If you are managing the machine you are running on, you can run:
sudo usermod -aG docker "$USER"Don't forget to restart your terminal to apply the change, and then try again.
Design requirements
In this series of chapters, we present the main context for Brane: its rationale, the setting and use-case for which it is developed and, finally, the design restrictions and requirements for designing it.
First, in the background chapter, the context and rationale of Brane is explained. Then, we discuss the setting and use-case of Brane, which then allows us to state a set of restrictions and requirements for its design.
If you are eager to read to how Brane actually works, you can also skip ahead to the design series of chapters.
Background
This chapter will be written soon.
Context & Use-case
Requirements
In the first- and second chapters in this series, we defined the context and use cases for which Brane was designed. With this in mind, we can now enumerate a set of requirements and assumptions that Brane has to satisfy.
This is because ... (Assumption A2)or
This is a consequence of ... (Requirement B1)used in other chapters in this book to refer to assumptions and requirements defined here, respectively.
Usage in High-Performance Computing (HPC)
Brane's original intended purpose was to homogenise access to various compute clusters and pool their resources. Moreover, the original project focused on acknowledging the wide range of knowledge required to do HPC and streamline this process for all parties involved. As such, it is a framework that is intended to do heavy-duty work on large datasets with a clean separation of concerns.
First, we specify more concretely what kind of work Brane is intended to perform:
Assumption A1
HPC nowadays mostly deals with data processing pipelines, and as such Brane must be able to process these kind of pipelines (described by workflows).
However, as the data pipelines increase in complexity and required capacity, it becomes more and more complex to design and execute the workflows representing these pipelines. It is assumed that this work can be divided into the following concerns:
Assumption A2
To design and execute a data pipeline, expertise is needed from a (system) administrator, to manage the compute resources; a (software) engineer, to implement the required algorithms; and a (domain) scientist, to design the high-level workflow and analyse the results.
Tied to this, we state the following requirement on Brane:
Requirement A1
Brane must be easy-to-use and familiar to each of the roles representing the various concerns.
This leads to the natural follow-up requirement:
Requirement A2
To fascilitate a clear separation of concerns, the roles must be able to focus on their own aspects of the workflow; Brane has the burden to bring everything together.
Requirement A2 reveals the main objective of the Brane framework as HPC middleware: provide intuitive interfaces for all the various roles (the frontend) and combine their efforts into the execution of a workflow on various compute clusters (the backend).
Further, due to the nature of HPC, we can require that:
Requirement A3
Brane must be able to handle high-capacity workflows that require large amounts of compute power and/or process large amounts of data.
Finally, we can realise that:
Assumption A3
HPC covers a wide variety of topics and therefore use-cases.
Thus, to make Brane general, it must be very flexible:
Requirement A4
Brane must be flexible: it must support many different, possibly use-case dependent frontends and as many different backends as possible.
To realise the last requirement, we design Brane as a loosely-coupled framework, where we can define frontends and backends in isolation as long as they adhere to the common specification.
Usage in healthcare
In addition to the general HPC requirements presented in the previous section, Brane is adapted for usage in the medical domain (see background). This introduces new assumptions and requirements that influence the main design of Brane, which we discuss in this section.
Most importantly, the shift to the medical domain introduces a heterogeneity in data access. Specifically, we assume that:
Assumption B1
Organisations often maximise control over their data and minimize their peers' access to their data.
This is motivated by the often highly-sensitive nature of medical data, combined with the responsibilities of the organisations owning that data to keep it private. Thus, the organisations will want to stay in control and are typically conservative in sharing it with other domains.
From this, we can formulate the following requirement for Brane:
Requirement B1
Domains must be as autonomous as possible; concretely, they cannot be forced by the orchestrator or other domains (not) to act.
To this end, the role of the Brane orchestrator is weakened from instructing what domains do to instead requesting what domains do. Put differently, the orchestrator now merely acts as an intermediary trying to get everyone to work together and share data; but the final decision should remain with the domains themselves.
In addition to maximising autonomy, recent laws such as GDPR [1] open the possibility that rules governing data (e.g., institutional policies) may be privacy-sensitive themselves. For example, Article 17.2 of the GDPR states that "personal data shall, with the exception of storage, only be processed with the data subject's consent". However, if this consent is given for data with a public yet sensitive topic (e.g., data about the treatment of a disease), then it can easily be deduced that the data subject's consent means that the patient suffers from that disease.
This leads to the following assumption:
Assumption B2
Rules governing data access may be privacy-sensitive, or may require privacy-sensitive information to be resolved.
This prompts the following design requirement:
Requirement B2
The decision process to give another domain access to a particular domain's data must be kept as private as possible.
Note, however, that by nature of these rules it is impossible to keep them fully private. After all, there is exist attacks to reconstruct the state of a state machine by observing its behaviour [2]; which means that enforcing the decision process necessarily offers opportunity for any attacker to discover them. However, Brane can give opportunity for domains to hide their access control rules by implementing an indirection between the internal behaviour of the decision process and an outward interface (see [3] for more information).
Because it becomes important to specify the rules governing data access properly and correctly, we can extend Assumption A2 to include a fourth role (the extension is emphasised):
Assumption B3
To design and execute a data pipeline, expertise is needed from a (system) administrator, to manage the compute resources; a policy expert, to design and implement the data access restrictions; a (software) engineer, to implement the required algorithms; and a (domain) scientist, to design the high-level workflow and analyse the results.
Finally, for practical purposes, though, the following two assumptions are made that allow us a bit more freedom in the implementation:
Assumption B4
A domain always adheres to its own data access rules.
(i.e., domains will act rationally and to their own intentions); and
Assumption B5
Whether data is present on a domain, as well as data metadata, is non-sensitive information.
(i.e., the fact that someone has a particular dataset is non-sensitive; we only consider the access control rules to that data and its contents as potentially sensitive information).
Next
In this chapter, we presented the assumptions and requirements that motivate and explain Brane. This builds upon the general context and use-cases of Brane, and serves as a background for understanding the framework.
Next, you can start examining the design in the Brane design chapter series. Alternatively, you can also skip ahead to the Framework specifiction if you are more implementation-oriented.
Alternatively, you can also visit the Appendix to learn more about the tools surrounding Brane.
References
[1] European Commission, Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation) (Text with EEA relevance) (2016).
[2] F. W. Vaandrager, B. Garhewal, J. Rot, T. Wiẞmann, A new approach for active automata learning based on apartness, in: D. Fisman, G. Rosu (Eds.), Tools and Algorithms for the Construction and Analysis of Systems - 28th International Conference, TACAS 2022, Held as Part of the European Joint Conferences on Theory and Practice of Software, ETAPS 2022, Munich, Germany, April 2-7, 2022, Proceedings, Part I, Vol. 13243 of Lecture Notes in Computer Science, Springer, 2022, pp. 223–243. doi:10.1007/978-3-030-99524-9_12. URL http://dx.doi.org/10.1007/978-3-030-99524-9_12
[3] C. A. Esterhuyse, T. Müller, L. T. van Binsbergen and A. S. Z. Belloum, Exploring the enforcement of private, dynamic policies on medical workflow execution, in: 18th IEEE International Conference on e-Science, e-Science 2022, Salt Lake City, UT, USA, October 11-14, 2022, IEEE, 2022, pp. 481-486
Introduction
Bird's-eye view
In this chapter, we provide a bird's-eye view of the framework. We introduce its centralised part (the orchestrator), decentralised part (a domain) and the components that each of them make up.
The components are introduced in more detail in their respective chapters (see the sidebar to the left). Here, we just globally specify what they do to understand the overarching picture.
Finally, note that the discussion in this chapter is on the current implementation, as given in the framework repository. Future work is discussed in its own series of chapters, which is a recommended read for anyone trying to do things like bringing Brane in production.
The task at hand
As described in the Design requirements, Brane is primarily designed for processing data pipelines in an HPC setting. In Brane, these data pipelines are expressed as workflows, which can be thought of as high-level descriptions of a program or process where individual tasks are composed into a certain control flow, linking inputs and outputs together. Specific details, such as where a task is executed or exploiting parallelism, is then (optionally) left to the runtime (Brane, in this case) to deduce automatically.
A workflow is typically represented as a graph, where nodes indicate tasks and edges indicate some kind of dependency. For Brane, this dependency is data dependencies. An example of such a graph can be found in Figure 1.
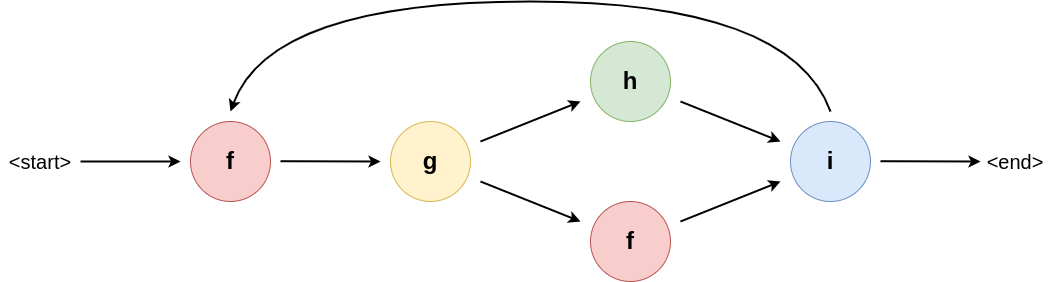
Figure 1: An example workflow graph. The node indicate a particular function, where the arrows indicate how data flows through them (i.e., it specifies data dependencies). Some nodes (i in this example), may influence the control flow dynamically to introduce branches or loops.
At runtime, Brane will first plan the workflow to resolve missing runtime information (e.g., which task is executed where). Then, it starts to traverse the workflow, executing each task as it encounters them until the end of the workflow is reached.
The tasks, in turn, can be defined separately as some kind of executable unit. For example, these may be executable files or containers that can be send to a domain and executed on their compute infrastructure. This split in being able to define workflows separately from tasks aligns well with Brane's objective of separating the concerns (Assumption B3) between the scientists and software engineers.
A federated framework
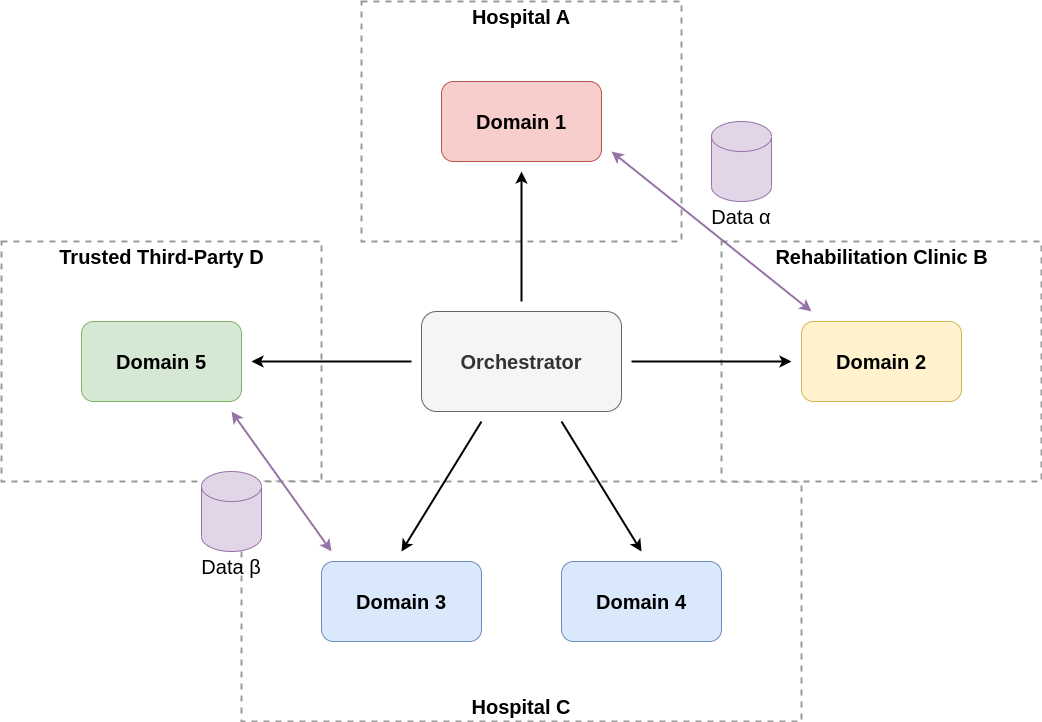
Figure 2: An overview of the framework services and how information flows between them. The Brane orchestrator communicates with domains to have them execute jobs or transfer data. Every domain can be thought of as one organisation, but not necessarily distinct (e.g., Hospital C has multiple domains).
Brane is a federated framework, with a centralised orchestrator that manages the work that decentralised domains perform (see Figure 2). This orchestrator does so by sending control messages to various domains, which encodes requests to perform a task on a certain data or exchange certain data with other domains. Importantly, these control messages only contain data metadata, which is assumed to be non-sensitive (Assumption B5); the actually sensitive contents of the data is only exchanged between domains when the domains decide to do so.
In this design, in accordance with Requirement B1, Brane does not attempt to control the domains themselves. Instead, it defines the orchestrator and what kind of behaviour the domain should display if it's well-behaved. However, because of the autonomy of the domains, no guarantees can be made about whether the domains are actually well-behaved; and as such, Brane is designed to allow well-behaving domains to deal with misbehaving domains.
The components of Brane
The Brane framework is defined in terms of components, each of which has separate responsibilities in achieving the functionality of the framework as a whole. They could be thought of as services, but components are more high-level; in practise, a component can be implemented by many services, or a single service may implement multiple components.
Because Brane is federated, the components are grouped similarly. There are central components, which live in the orchestrator and work on processing workflows and emitting (compute) events; and there are local components that live in each domain and work on processing the emitted events.
An overview of the components can be found in Figure 3.
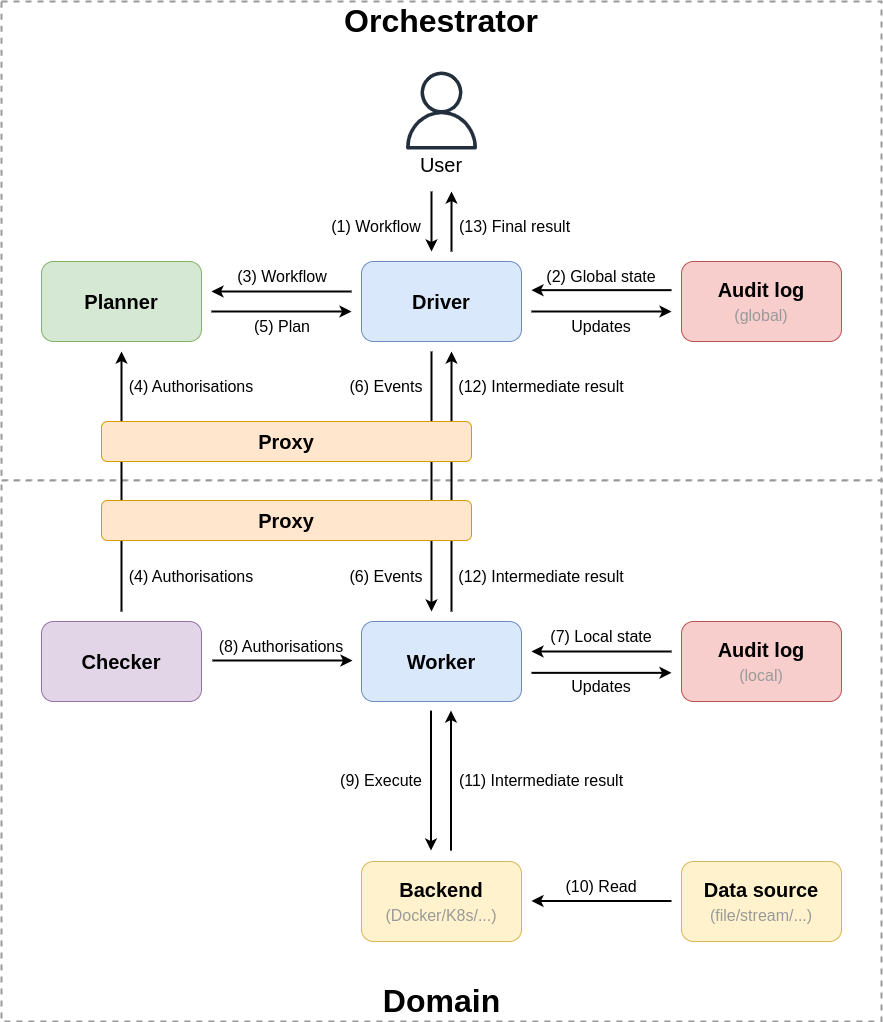
Figure 3: An overview of Brane's components, separated in the central plane (the orchestrator) and the local plane (the domains). Each node represents a component, and each arrow some high-level interaction between them, where the direction indicates the main information flow. The annotation of the arrows give a hint as to what is exchanged and in what order. Finally, the colours of the nodes indicate a flexible notion of similarity.
Central components
The following components are defined at the central orchestrator:
- The driver acts as both the entrypoint to the framework from a user's perspective, and as the main engine driving the framework operations. Specifically, it takes a workflow and traverses it to emit a series of events that need to be executed by, or otherwise processed on, the domains.
- The planner takes a workflow submitted by the user and attempts to resolve any missing information needed for execution. Most notably, this includes assigning tasks to domains that should execute them and input to domains that should provide them. However, this can also include translating internal representations or adding additional security. Finally, the planner is also the first step where policies are consulted.
- The global audit log keeps track of the global state of the system, and can be inspected both by global components and local components (the latter is not depicted in the figure for brevity).
- The proxy acts as a gateway for traffic entering or leaving the node. It is more clever than a simple network proxy, though, as it may also enforce security, such as client authentication, and acts as a hook for sending traffic through Bridging Function Chains.
Local components
Next, we introduce the components found on every Brane domain. Two types of components exist: Brane components and third-party components.
First, we list the Brane components:
- The worker acts as a local counterpart to the global driver. It takes events emitted by the driver and attempts to execute them locally. An important function of the worker is to consult various checkers to ensure that what it does it in line with domain restrictions on data usage.
- The checker is the decision point where a domain can express restrictions on what happens to data they own. At the least, because of Assumption B4, the checker enforces its own worker's behaviour; but if other domains are well-behaved, the checker gets to enforce their workers too. As such, the checker must also reason about which domains it expects to act in a well-behaved manner and thus allow them to access its data.
- The local audit log acts as the local counterpart of the global audit log. As the global log keeps track of the global state, the local log keeps track of local state; and together, they can provide a complete overview of the entire system.
- The proxy acts as a gateway for traffic entering or leaving the node. It is more clever than a simple network proxy, though, as it may also enforce security, such as client authentication, and acts as a hook for sending traffic through Bridging Function Chains.
The third-party components:
- The backend is the compute infrastructure that can actually execute tasks and process datasets. Conceptually, every domain only has one, although in practise it depends on the implementation of the worker. However, they are all grouped as one location as far as the planner is concerned.
- The data sources are machines or other sources that provide the actual data on which the tasks are executed. Their access is mostly governed by checkers, and they can supply data in many forms. From a conceptual point of view, every data source is a dataset, which can be given as input to a task - or gets created when a task completes to represent an output.
Implementing components
In the reference implementation, the components discussed in the previous section are implemented by actual services. These really are concrete programs that may run on a set of hosts to implement the functionality of the Brane framework.
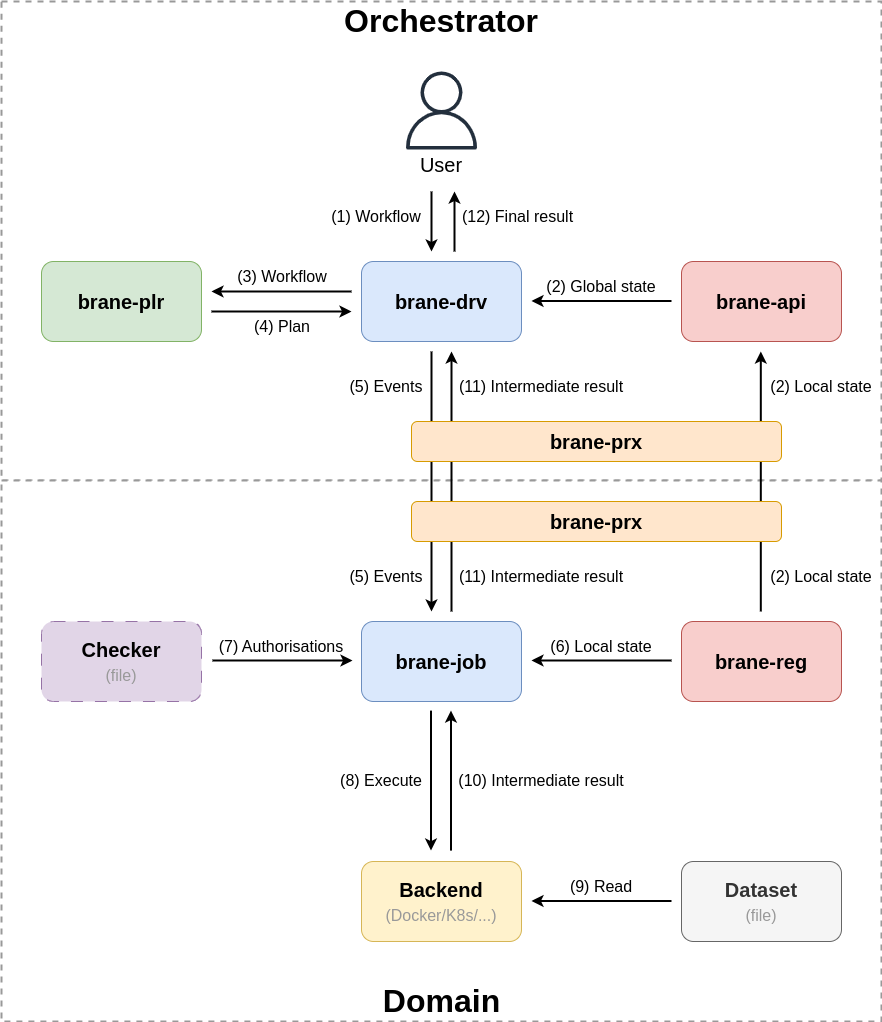
Figure 4: An overview of Brane's services as currently implemented. Every node now represents a service, at the identical location as the component they implement but with the name used in the repository. Otherwise, the figure can be read the same way as Figure 3.
Figure 4 shows a similar overview as Figure 3, but then for the concrete implementation instead of the abstract components. Important differences are:
- Checkers are purely virtual, and implemented as a static file describing the policies.
- Planners do not consult the domain checker files, but instead create plans without knowledge of the policies. Instead, the planner relies on workers refusing to execute unauthorised plans.
- The audit logs are simplified as registries, of which the global one (
brane-api) mirrors the local ones (brane-reg) for most information. - Data is only available as files or directories, not as generic data sources.
Next
The remainder of this series of chapters will mostly discuss the functionality of the reference implementation. To start with, head over to the description of the individual services, or skip ahead to which protocols they implement.
After this, the specification defines how the various components can talk to each other in terms such that new services implementing the components may be created. Then, in the Future work series of chapters, we discuss how the reference implementation can be improved upon to reflect the component more accurately and practically.
Aside from that, you can also learn more about the context of Brane or its custom Domain-Specific Language, BraneScript.
Virtual Machine (VM) for the WIR
An important part of the the Brane Framework is the execution engine for the Workflow Intermediate Representation (WIR). Because the WIR is implemented as a binary-like set of edges and instructions, this execution engine is known as a Virtual Machine (VM) because it emulates a full set of resources needed to execute the WIR.
In these chapters, we will discuss the reference implementation of the VM. Note that it is assumed that you are already familiar with the WIR and have read the matching chapters in this book.
VM with plugins
In Brane, a workflow might be executed in different contexts, which changes what effects a workflow has.
In particular, if we think of executing a workflow as translating it to a series of events that must be processed in-order, then how we process these events differs on the execution environment. In brane-cli, this environment is on a single machine and for testing purposes only; whereas in brane-drv, the environment is a full Brane instance with multiple domains, different backends and policies to take into account.
To support this variety of use-cases, the VM has a notion of plugins that handle the resulting events. In particular, the traversal and processing of a workflow is universalised in the base implementation of the VM. Then, the processing of any "outward-facing" events (e.g., task processing, file transfer, feedback to user) is delegated to configurable pieces of code that handle these different based on the use-case.
Source code
In the reference implementation, the base part of the VM is implemented in the brane-exe-crate. Then, brane-cli implements plugins for a local, offline execution, whereas brane-drv implements the plugins for the in-instance, online execution. Finally, a set of dummy plugins for testing purposes exists in brane-exe as well.
Next
In the next chapter, we start by considering the main structure and overview of the VM, including how the VM handles threads and plugins. Then, we examine various implementations of subsystems: the expression stack (including the VM's notion of values), the variable register and the frame stack (including virtual symbol tables).
If you're interesting in another topic than the VM, you can select it in the sidebar to the left.
Overview
In this chapter, we discuss the main operations of the Brane VM.
Note that we mostly focus on the global operations, and not on how specific Edges or EdgeInstructions of the WIR are executed. Those are implemented as discussed in the WIR specification (mostly).
Running threads
In its core, the VM is build as a request processing system, since that is the main functionality of the brane-drv: workflows come in as disjoint requests that can be processed separately and in parallel.
As such, the VM has to balance multiple threads of execution. Each of these represent a single workflow or, more low-level, a single graph of edges that the VM has to traverse. However, these threads are completely isolated from each other; it is assumed that they do not interfere with each other during execution. This is made possible by considering datasets to be immutable1.
Practically, the threads of the VM are executed as Rust Futures (roughly analogous to JavaScript Promises). This means that no explicit management of threads is found back in the codebase, or indeed in the rest of the description of the VM (parallel-statements excempted). Instead, they are handled implicitly by virtue of multiple requests coming in in parallel.
Every thread, then, acts as a single-minded VM executing only a single workflow. This representation is visualized in Figure 1.
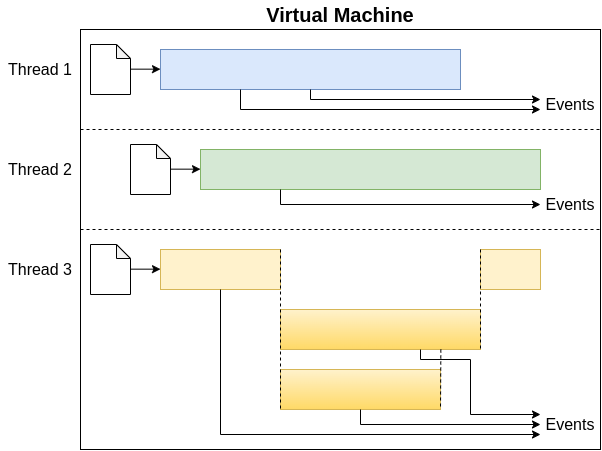
Figure 1: Visualisation of the Virtual Machine and its threads. The VM executes multiple threads in parallel, each originating from its own workflow. Threads themselves then unspool a workflow into a series of events, such as giving feedback to the user or executing tasks. Sometimes, threads may also be spawned as the result of a fork (e.g., parallel statements; thread 3).
Practically, however, datasets aren't completely immutable because their identifier can be re-bound to a new version of it. That way, threads can interfere with each other by re-assigning the identifier as another thread wants to use it. This is not fixed in the reference implementation.
Unspooling workflows
Threads process workflows as graphs. Given one (or given a sub-part of the workflow, as in the case of fork), they traverse the graph as dictated by its structure. Because workflows can be derived from scripting-like languages, the traversing can include dynamic control flow decisions. To this end, a stack is used to represent the dynamic state, as well as a variable register, to emulate variables, and a frame stack, to support an equivalent of function calls.
As the workflow gets traversed, threads encounter certain nodes that require emitting certain events; this are first emitted internally to be caught by the chosen plugin. Then, the plugin re-emits them for correct processing: for example, this can be emitted as a print-statement for the user or as a task execution on a certain domain.
How the workflow is traversed exactly is described in the WIR specification.
VM plugins
As mentioned in the previous chapter, does the VM rely on plugins to change how it emits events that occur as the workflow is processed. These plugins change, for example, how a task is scheduled; in the local case, it is simply pushed to the local container daemon, whereas in the global case, it is sent as a request to the domain in question.
The plugins are implemented through a Rust trait (i.e., an interface). Then, which plugin is used can be changed statically by assigning a different type to the VM when it is instantiated; the compiler will then take care to generate a version of the VM that uses the given plugin. Because this is done statically, it is very performant but not very flexible (i.e., plugins cannot be changed at runtime, only at compile time).
Next
With this overview in mind, we will next examine the expression stack, before continuing with the variable register and frame stack.
You can also select another topic in the sidebar on the left.
Expression stack
In this chapter, we will discuss the reference implementation's implementation of the expression stack for the Virtual Machine (VM) globally introduced in the previous chapter. Because it is a thread that will execute a single workflow, we will discuss the stack's behaviour in the context of a thread.
First, we will discuss the basic view of the stack, after which we discuss the stack's notion of values (including dynamic popping).
Basic view
The stack acts as a scratchpad memory for the thread to which it belongs. As the thread processes graph edges and their attached instructions, these may push values on the stack of pop values from them. This is done in FIFO-order, i.e., pushing adds new values on top of the stack, whereas popping removes them in reverse order (newest first). Typically, instructions consume values, perform some operation on them and then push them back. This is visualised in Figure 1.
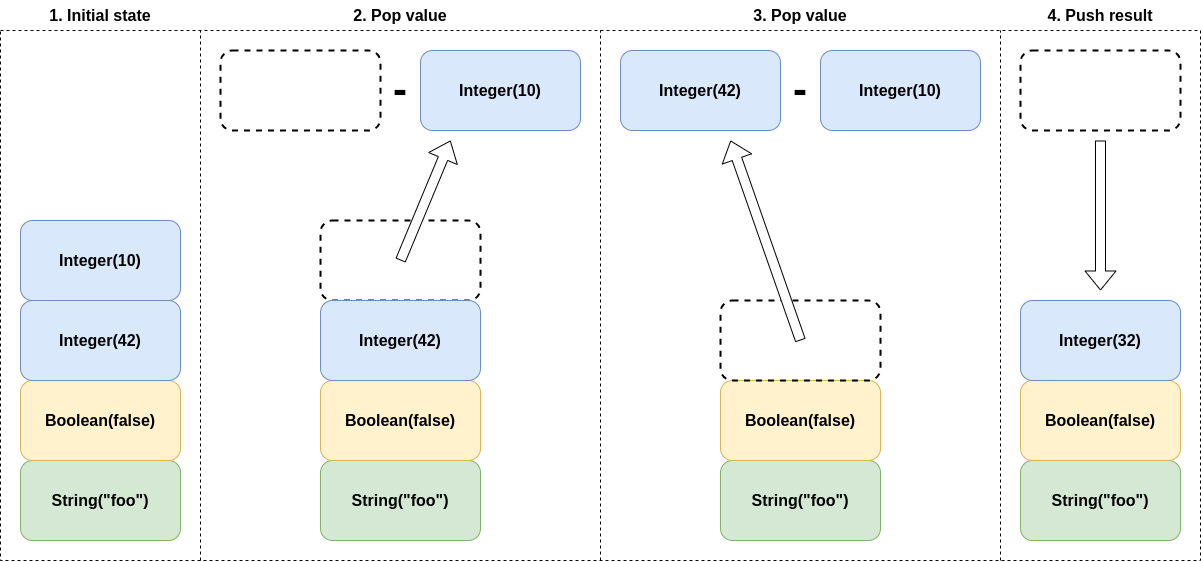
Figure 1: Visualisation of an arithmetic operation (subtraction) on the stack. Operations are defined as rewrite rules on the top values of the stack, popping input as necessary and pushing results as computed. In this example, note that possibly counter-intuitive ordering of arguments due to the FIFO nature of the stack.
Some edges, then, may introduce conditionality by taking one of multiple next possible branches in the tree. Which branch is taken then depends on the top value of the stack, which typically uses a boolean true to denote that the branch should be taken or a boolean false to denote it shouldn't.
Note that the stack in the implementation is relatively simple. It is bounded to a static size (allowing Stack overflow errors to potentially occur), and it does not store large objects, such as strings, arrays and instances, by reference but instead by value. This means that, everytime an operation is performed on such an object, the object needs to be re-created or copied instead of simply pushing a handle to it.
Value's and FullValue's
The things stored on the stack are valled values, and represent one particular value that is used or mutated in expressions and/or stored in variables (see the next chapter). Specifically, values in the stack are typed, and may be of any data type defined in the WIR except any grouping of types, including DataType::Any. This latter implies that all types will be resolved at runtime, even if they aren't always known beforehand in the given workflow.
Note, however, that the values on the stack do not embed their type information completely. Customized information, such as a class definition or function header, lives on the frame stack and is scoped to the function that we're calling. As such, values only contain identifiers to the specific definition currently in scope.
There exists a variant of value's, full values, which do embed their definitions. These are used when values are communicated outside of the VM, such as return values of workflows.
Dynamic popping
A special case of value on the stack is a dynamic pop marker, which is used in dynamic popping. This is used when the return value of a function cannot be typed at runtime, and an unknown number of items have to be popped from the stack after the function returns.
To this end, the pop marker is used. First, it is pushed to the stack before the function call; then, when executing a dynamic pop, the stack will simply pop values until it has popped the dynamic pop marker. For all other operations, the pop marker is invisible and acts as though the value below it is on top of the stack instead.
Next
In the next chapter, we discuss the next component of the VM, the variable register. The frame stack will be discussed after that.
If you like have an overview of what the VM does as a whole, check the previous chapter. You can also select a different topic altogether in the sidebar to the left.
Variable register
![]()
VariableRegister in brane-exe/varreg.rs./
In the previous chapter, we introduced the expression stack as a scratchpad memory for computing expressions as a thread of the VM executes a workflow. However, this isn't always suitable for all purposes. Most notably, the stack only allows operations on the top values; this means that if we want to re-use arbitrary values from before, this cannot be represented by the stack alone.
To this end, a variable register is implemented in the VM that can be used to temporarily store values on another location outside of the stack altogether. Then, the values in these variables can be pushed to the stack whenever they're required.
Implementation
The variable register is implemented as an unordered map of variable identifiers to values. Like values, the variable register does not store variables by name but rather by definition, as found in the workflow's definition table. As such, the map is keyed by numbers indexing the table instead of its name. The definition in the definition table, then, defines the variable's name and type.
The variables in the register can have one of three states:
- Undeclared: the variable does not appear in the register at all;
- Declared but uninitialized: the variable appears in the register but have a null-value (Rust's
None-value); or - Initialized: the variable appears in the register and has an actualy value.
The reason for this is that variables are typed, and that they cannot change type. In most cases, variables will have their types annotated in their definition; but sometimes, if this cannot be determined statically, then a variable will assume the type of the first value its given until it is undeclared and re-declared again.
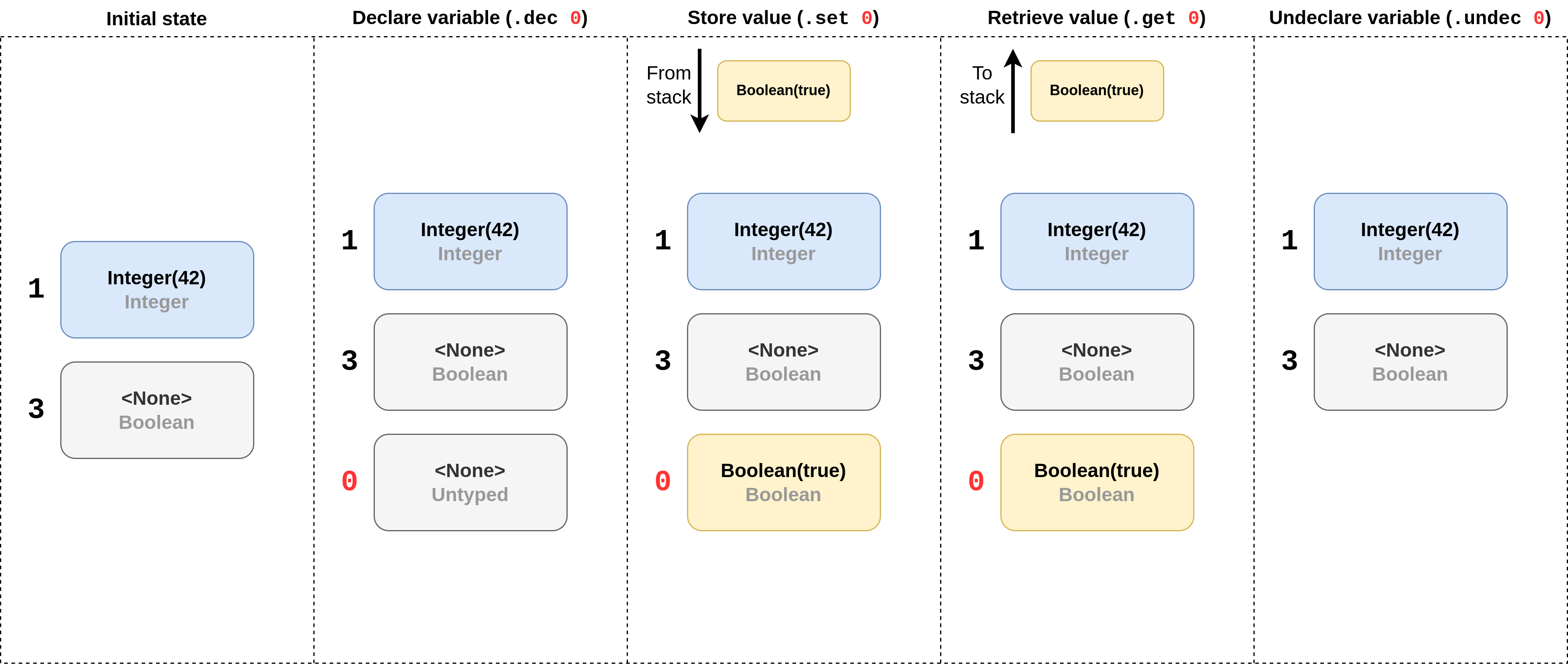
Figure 1: Visualisation of the possible variable register operations. Variables are stored by ID, and can either have a value or <None> to represent uninitialized. When a new variable is declared, the ID is looked up in the workflow definition table, and the slot is typed according to the variable's static type. Otherwise, (as is the case for 0), the type is set when the variable is initialized. Further operations must always use that type until the variable is undeclared and re-declared.
Next
The next chapter will see the discussion of the frame stack, the final of the VM's state-components. In the chapter after it, we will showcase how the components operate together when executing a simple workflow.
For an overview of the VM as a whole, check the first chapter in this series. You can also select a different topic altogether in the sidebar to the left.
Frame stack
![]()
FrameStack in brane-exe/frame_stack.rs.
In the previous chapters, the expression stack and the variable register were introduced. In this chapter, we will introduce the final state component of the VM: the frame stack. After this, we have enough knowledge to examine a full VM execution in the final chapter of this series.
The frame stack is a FIFO-queue, like the expression stack. However, where the expression stack acts as a scratchpad memory for computations, the frame stack's utility lies with function calls, and keeps track of which calls have been made and -more importantly- where to return to when a Return-edge is encountered. Finally, the frame stack also keeps track of the function return type (if known) for an extra type check upon returning from a function.
Implementation
The frame stack is implemented as a queue of frames, which each contain information about the context of a function call. In particular, frames store three things:
- A reference to the function definition (in the workflow's definition table) of the called function;
- A list of variables (as references to variable definitions in the definition table) that are scoped to this function. When the function returns, these variables will be undeclared; and
- A pointer to the edge to execute after the function in question returns. Note that this points to the next edge to execute, i.e., the edge after the call itself.
Other than that, the frame stack pretty much acts as a stack for calls. A visualisation of this process is given in Figure 1.
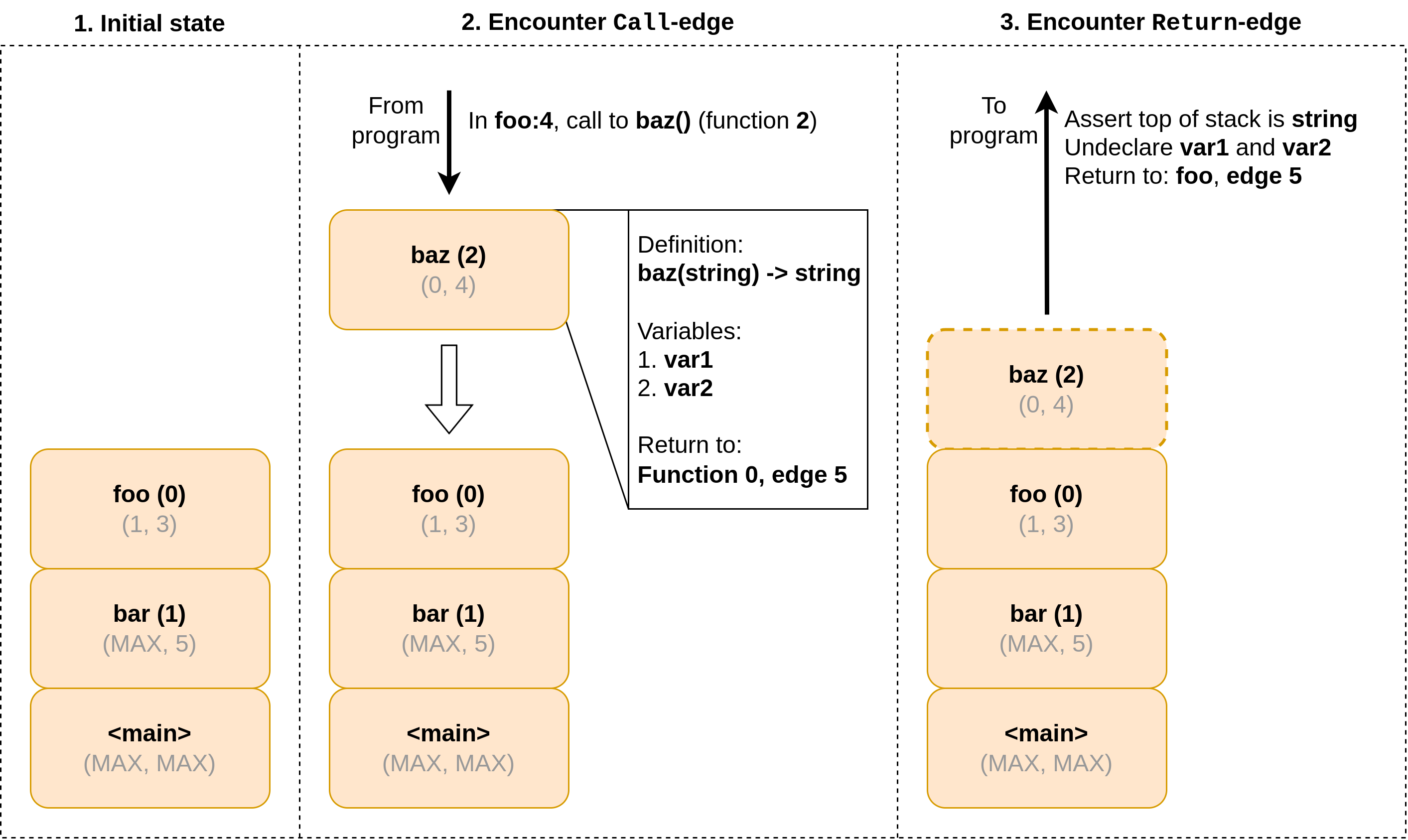
Figure 1: Visualisation of the frame stack operations. Elements on the stack (frames) are pushed for every call and popped for every return. Frames describe the behaviour of return in terms of return type, variable undeclaration and which address to return to. Note the address returns to the edge after the call, not the call itself.
Typing scopes
In Brane versions 3.0.0 and earlier, the frame stack had the secondary goal of maintaining which type definitions (functions, tasks, classes and variables) were currently in scope. In particular, WIR-workflows were written with a per-function definition table, which added definitions local to that function only to the current scope.
In that context, the frame stack frames included the function's definition table, along with mechanisms for resolving the stack of tables into a coherent scope. As such, in the reference implementation's code, the frame stack also provides access to all definitions of the workflow to the rest of the VM.
However, this proved to be extremely complicated in practise, and is phased out in versions later than 3.0.0. Now, there is just a single table at the start of the workflow that contains all definitions occurring. For compatability reasons, the frame stack still contains a pointer to that table and provides access to it in the codebase.
Next
In the next chapter, all three separate VM components (expression stack, variable register and frame stack) are used to showcase an example execution for the VM. That will conclude this series of chapters.
Alternatively, you can also select another topic in the sidebar to the left.
Bringing it together
In the previous few chapters, various components of the VM have been discussed that together make up the VM's state. To showcase how this state is used, this section emulates the run of a VM to see how a particular program is processed and changes the state.
The workflow that we will execute can be examined here. A recommended way to read this chapter is to familiarize yourself with the workflow first (in any of the three representations), and then read the example below. You can open the workflow in a separate tab to refer to it, if you wish.
Example
The execution of the workflow is described in three parts: first, we will examine the initial state of the VM; then, we emulate one of the function calls in the workflow; after which we do the remainder of the workflow in more high-level and examine the result.
Initial state
The state of the VM is expressed in four parts:
- The program counter, which points to the next edge/instruction to execute;
- The expression stack;
- The variable register; and
- The frame stack.
Throughout the example, we will display the state of these components as they get updated. For example, this is the VM's state at start:
Program counter
// We give the program counter as a triplet of (<func>, <edge>, <instr_or_null>) // Remember that `MAX` typically refers to `<main>` // Points to the first instruction in the first Linear edge in `<main>` (MAX, 0, 0)Expression stack
// The expression stack is given as a list of values (empty for now) [ ]Variable register
// The variable register is given as a map of variable names to the contents // for that variable (empty for now) { }Frame stack
// The frame stack is given as a list of frames [ // Every frame is: function, variables (as name, type), return address { // Remember that `MAX` typically refers to `<main>` "func": MAX, // Lists all variables declared in this function's body "vars": [ ("zeroes", "IntermediateResult"), ("ones", "IntermediateResult"), ], // See 'Program counter', or null for when there is no return address "pc": null } ]
Most state is empty, except for the program counter, which points to the first edge in the first function; and the frame stack, which contains the root call made by the VM to initialize everything.
Function call
If we examine the workflow, the first edge we encounter is a Linear edge. This contains multiple instructions, and so the VM will execute these first.
Note that every step has an implicit update to the program counter at the end. For example, step 1.1 ends with:
Program counter
(MAX, 0, 1) // Note the bump in the instruction!
and step 1 as a whole ends with:
Program counter
(MAX, 1, 0) // Note the bump in the edge!
We will only note it when changes to typical bumping happen (e.g., function call).
-
Linear-edge: To process a linear edge, the instructions within are executed.-
.dec zeroes: The first instruction is to declare thezeroes-variable, as the start of the function (in this case,<main>). As such, this creates an entry for it in the variable register:Variable register
{ // The entry for the `zeroes`-variable. 4: { "name": "zeroes", "type": "IntermediateResult", "val": null } }(Refer to the workflow table in Listing 2 to map IDs to variables)
The variable is declared (part of the register) but not initialized (
valisnull). -
.int 3: Next, we begin by computing the argument to the first function calls, which is3 + 3. As such, the next instruction pushes a3integer constant to the expression stack. The stack looks as follows after executing it:Expression stack
[ { // The data type of this entry on the stack. "dtype": "int", // The integer value stored. "value": 3, } ] -
.int 3: Another integer constant is pushed (3again). The stack looks as follows after executing it:Expression stack
[ // The new entry (so we reversed the order of the list) { "dtype": "int", "value": 3, }, { "dtype": "int", "value": 3, } ] -
.add: We perform the addition to complete the expression3 + 3in the workflow. This pops the top two values, adds them, and pushes the result to the stack. Therefore, this is the expression stack after the addition has been performed:Expression stack
[ // We've just done `3 + 3` :) { "dtype": "int", "value": 6, } ] -
.func generate_dataset: With the arguments to the function call prepared on the stack, the next step is to push what we will be calling. As such, the top of the stack will be a pointer to the function that will be executed.Expression stack
[ { "dtype": "function", // Note that the function is represented by its identifier "def": 4, }, { "dtype": "int", "value": 6, } ]Now, we are ready for a function call. However, since this control flow deviation must be visible to checkers who want to validate the workflow, this is represented at the Edge-level. The next thing to execute is thus a next edge.
-
-
Call-edge: The Call will first pop the function pointer from the stack and resolves it to a function definition in the workflow's definition table. In this case, it will check function4and see that it'sgenerate_dataset. Based on its signature, it knows that the top of the stack must contains a value ofAnytype; and as such, it will assert this is the case. This means that the expression stack looks like:Expression stack
[ // Only the pointer is popped; the arguments are for the function to figure out { "dtype": "int", "value": 6, } ]Next, a new frame is pushed to the frame stack that allows us to handle any
Return-edges appropriately:Frame stack
[ { // We're calling function 4 (generate_dataset)... "func": 4, // ...which will declare the variables `n` "vars": [ ("n", "Any"), ], // ...and return to the next Edge after the call (the second Linear in `<main>`) "pc": (MAX, 2, 0) }, { "func": MAX, "vars": [ ("zeroes", "IntermediateResult"), ("ones", "IntermediateResult"), ], "pc": null } ]Once the expression stack and frame stack check out, the call is performed; this is done by changing the program counter to point to the called function:
Program counter
(4, 0, 0) // First Edge, first instruction in function 4 (generate_dataset)This means that the next edge executed is no longer the next one in the main function body, but rather the first one in the called function's body.
Function body
Next, the function body of the generate_dataset function (i.e., function 4) is executed by the VM.
-
Linear-edge:-
.dec n: The first step when the function body is entered is to map the arguments on the stack to named variables. To do that, the variable has to be declared first; and that's what happens here.
The variable register after declaration:Variable register
{ // The entry for the `n`-variable. 0: { "name": "n", "type": "Any", // Still uninitialized "val": null }, 4: { "name": "zeroes", "type": "IntermediateResult", "val": null } } -
.set n: With the variable declared, we can pop the top value off the expression stack and move it to the variable's slot in the variable register.
The expression stack is empty after performing the.set:Expression stack
[ ]and instead, the value is now assigned to
n:Variable register
{ // The entry for the `n`-variable. 0: { "name": "n", // Because it was `Any`, the type of `n` has been set in stone now "type": "int", "val": 6 }, 4: { "name": "zeroes", "type": "IntermediateResult", "val": null } } -
.get n: After storing the arguments, the function call needs to be prepared now (which is a call tozeroes, using a number and a string). A disadvantage of the push/pop model is that, even if the value was just on top of the stack, we removed it to move it to the variable register. Therefore, we need to add it again to use in the next function call:Expression stack
[ { "dtype": "int", "value": 6, } ]Note that the variable register is actually not edited, as
.gets perform copies. -
.cast Integer: Before moving to the next argument of the call, a cast is used by the compiler to have the VM assert the current value on the stack is convertible to the required integer. In addition, if the user uses a type trivially convertible to integers (e.g., booleans), then this cast steps is where this conversion happens.
However, as the value was already an integer, nothing changes and the VM continues. -
.str "vector": For the second argument to the function call, a string constant is used. This is pushed with this instruction.Expression stack
[ { "dtype": "string", "value": "vector", }, { "dtype": "int", "value": 6, } ]
-
-
Node-edge: Now it's time to perform the call tozeroes. However, sincezeroesis actually an external function instead of a BraneScript function, the VM cannot simply change program counters and continue execution. Instead, it will use its plugins to execute the node on whatever backend necessary.
To do so, first the arguments to the external function are popped from the expression stack:Expression stack
[ // They're being processed now ]The VM will then perform the call using the information supplied in the
Nodeand the values supplied by the function arguments. This process is described in TODO.
When the execution completes, the result is pushed onto the stack:Expression stack
[ // The result is a reference to a created dataset { "dtype": "IntermediateResult", // This ID is randomly generated by the compiler "value": "result_foo", } ]Then, execution of the graph continues as normal, as if the call returned immediately.
-
Return-edge: After the task has been processed, thegenerate_datasetfunction completes.
When a Return-edge is executed, it first pops the current frame from the frame stack to examine what to do next:Frame stack
[ // Only the main frame remains { "func": MAX, "vars": [ ("zeroes", "IntermediateResult"), ("ones", "IntermediateResult"), ], "pc": null } ]Based on this, the VM now first removes the variables from the variable register that were local to this function:
Variable register
{ // Variable `n` is gone now... 4: { "name": "zeroes", "type": "IntermediateResult", "val": null } }Then, based on the definition of the called function, the VM examines if a value needs to be returned. If so, the expression stack is verified to see if this is indeed what is on top of the stack; and in this case, it will see that this is so.
The VM is now ready to jump back to the next edge in<main>, and thus updates the program counter accordingly:Program counter
(MAX, 2, 0) // Points back into `<main>`, to the second `Linear`and then it executes the program from there onwards.
More calls
-
Linear-edge: In the next edge in<main>, the embedded instructions make two things happen:- The result of the call to
generate_datasetis stored inzeroes(.set zeroes); and - The arguments to the next call (
add_const_to(2, zeroes)) are being prepared. This is done by first pushing the constant2, and then extending that with the value currently inzeroes.
After everything is processed, the variable register and expression stack look like:
Variable register
{ // Zeroes has been given a value 4: { "name": "zeroes", "type": "IntermediateResult", "val": "result_foo" }, // `ones` has been declared but uninitialized 5: { "name": "ones", "type": "IntermediateResult", "val": null } }Expression stack
[ // The stack now contains the arguments (first at the bottom), then the function pointer to call { "dtype": "function", "value": 5 }, { "dtype": "IntermediateResult", "value": "result_foo" }, { "dtype": "int", "value": 2 }, ] - The result of the call to
-
Call-edge: Theadd_const_tofunction is called, exactly like the previous function. We won't repeat the full call here, but instead just continue after the call returned.Expression stack
[ // The reference to the next result is on the stack, produced by `add_const`. { "dtype": "IntermediateResult", "value": "result_bar" } ] -
Linear-edge: The final call is being prepared in this Edge. This simply relates to storing the result of the previous call, and then callingcat_dataon it.Variable register
{ 4: { "name": "zeroes", "type": "IntermediateResult", "val": "result_foo" }, // `ones` has been updated with the result of the `add_const_to` call 5: { "name": "ones", "type": "IntermediateResult", "val": "result_bar" } }Expression stack
[ // The function to call and then the argument to call it with { "dtype": "function", "value": 6 }, { "dtype": "IntermediateResult", "value": "result_bar" } ] -
Call-edge: The call tocat_datais processed as normal, except that a special call happens inside of it; after thecat-task has been processed, its result isprintlned, which is a builtin function. This function makes the VM pop a value, and then print that to the stdout (or something similar) appropriate to the environment the VM is being executed in using one of its plugins. This means that it's not a full call using program counter jumps, but instead processing that happens in the Call itself.
Sincecat_dataitself does not return, the final state change of the program is that the expression stack is now empty:Expression stack
[ // All values have been popped ]
Result
Stop-edge: When this edge is reached, the VM quits and cleans up. This latter part is done implicitly by unallocating all of its resources.
This concludes the execution of our workflow, which has produced the output of the dataset on stdout. Any intermediate results will now be destroyed, and the entity managing the VM can do other stuff again.
Next
That concludes the chapters on the VM!
The next step could be examining how tasks are being executed on the rest of the Brane system (see the TODO-chapter). Alternatively, you can also learn more about BraneScript by going to the Appendix. Or you can select any other topic in the sidebar on the left.
Bringing it together - Workflow example
This page contains the workflow used in the Bringing it together chapter.
Three representations are given: BraneScript, WIR (using a more readable syntax than JSON) and a visual graph representation.
BraneScript
The snippet in Listing 1 shows the example workflow described using BraneScript.
// See https://github.com/epi-project/brane-std
import cat; // Provides `cat()`
import data_init; // Provides `zeroes()`
import data_math; // Provides `add_const()`
// Function to generate a dataset that is a "vector" of `n` zeroes
func generate_dataset(n) {
return zeroes(n, "vector");
}
// Function to add some constant to a dataset
func add_const_to(val, data) {
return add_const(data, val, "vector");
}
// Function to print a dataset
func cat_data(data) {
println(cat(data, "data"));
}
// Run the script
let zeroes := generate_dataset(3 + 3);
let ones := add_const_to(2, zeroes);
cat_data(ones);
Listing 1: The example workflow for the Bringing it together chapter. It is denoted in BraneScript.
WIR
The snippet in Listing 2 shows the equivalent WIR to the workflow given in Listing 1.
Table {
Variables [
0: n (Any),
1: val (Any),
2: data (Any),
3: data (Any),
4: zeroes (IntermediateResult),
5: ones (IntermediateResult),
],
Functions [
0: print(String),
1: println(String),
2: len(...),
3: commit_result(...),
4: generate_dataset(Any) -> IntermediateResult,
5: add_const_to(Any, Any) -> IntermediateResult,
6: cat_data(Any),
],
Tasks [
0: cat<1.0.0>::cat_range_base64(...),
1: cat<1.0.0>::cat_range(...),
2: cat<1.0.0>::cat(IntermediateResult, String) -> String,
3: cat<1.0.0>::cat_base64(...),
4: data_init<1.0.0>::zeroes(Integer, String) -> IntermediateResult,
5: data_math<1.0.0>::add_const(IntermediateResult, Real, String) -> IntermediateResult,
],
Classes [
0: Data { name: String },
1: IntermediateResult { .. },
]
}
Workflow [
<main> [
Linear [
.dec zeroes
.int 3
.int 3
.add
.func generate_dataset
],
Call,
Linear [
.set zeroes
.dec ones
.int 2
.get zeroes
.func add_const_to
],
Call,
Linear [
.set ones
.get ones
.func cat_data
],
Call,
Stop
],
func 4 (generate_dataset) [
Linear [
.dec n
.set n
.get n
.cast Integer
.str "vector"
],
Node<4> (data_init<1.0.0>::zeroes),
Return
],
func 5 (add_const_to) [
Linear [
.dec data
.set data
.dec val
.set val
.get data
.cast IntermediateResult
.get val
.cast Real
.str "vector"
],
Node<5> (data_math<1.0.0>::add_const),
Return
],
func 6 (cat_data) [
Linear [
.dec data
.set data
.get data
.cast IntermediateResult
.str "data"
],
Node<2> (cat<1.0.0>::cat),
Linear [
.func println,
],
Call,
Return
],
]
Listing 2: A WIR-representation of the workflow given in Listing 1. This snippet uses freeform syntax to be more readable than the WIR's JSON.
Graph
Figure 1 shows the visual representation of the workflow given in Listing 1 and Listing 2.
 Figure 1: Visual representation of the example workflow for the Bringing it together chapter. The workflow is described as a WIR-workflow, using WIR-graph elements and instructions.
Figure 1: Visual representation of the example workflow for the Bringing it together chapter. The workflow is described as a WIR-workflow, using WIR-graph elements and instructions.
Services
Brane is implemented as a collection of services, and in the next few chapters we will introduce and discuss every of them. As we do so, we also discuss algorithms and representation used in order to make sense of the services.
Central services
The services found in the central orchestrator are:
- brane-drv implements the driver and acts as both the entrypoint and execution engine to the rest of the framework.
- brane-plr implements the planner and is responsible for deducing missing information in the submitted workflow.
- brane-api implements the global audit log and provides global information to other services in the framework.
- brane-prx implements the proxy and fascilitates and polices inter-node communication.
The following services are placed on each domain:
- brane-job implements the worker and processes the incoming events from the driver.
- brane-reg implements the local audit log and provides local information to its
brane-joband the central registrybrane-api. It also implements partial worker functionality by fascilitating data transfers. - brane-prx implements the proxy and fascilitates and polices inter-node communication.
brane-drv: The driver
Arguably the most central to the framework is the brane-drv service. It implements the driver, the entrypoint and main engine behind the other services in the framework.
In a nutshell, the brane-drv-service waits for a user to submit a workflow (given in the Workflow Internal Representation (WIR)), prepares it for execution by sending it to brane-plr and subsequently executes it.
This chapter will focus on the latter function mostly, which is executing the workflow in WIR-format. For the part of the driver that does user interaction, see the specification; and for the interaction with brane-plr, see that service's chapter.
The driver as a VM
The reference implementation defines a generic Vm-trait that takes care of most of the execution of a workflow. Importantly, it leaves any operation that may require outside influence open for specific implementations;
This is done by following the procedure described in the next few subsections. First, we will discuss how the edges in a workflow graph are traversed and executed, after which we describe some implementation details of executing the instructions embedded within them. Then, finally, we will describe the procedure of executing a task from the driver's perspective.
Unspooling workflows
In the WIR specification, the workflow graph is defined as a series of modular "Edges" that compose the graph as a whole. Every such component can be thought of as having connectors, where it gets traversed from its incoming to one of its outgoing connectors. Which connector is taken, then, depends on the conditional branches embedded in the graph.
To execute the conditional branches, the driver defines a workflow-local stack on which values can be pushed to and popped from as the traversing of a workflow occurs.
The driver always starts at the first edge in the graph-part of the WIR, which represents the main body of the workflow to execute. Starting at its incoming connector, the edge is executed and the driver moves to the next one indicated by its outgoing connector. This process is dependent on which edge is taken:
Linear: As the name suggests, this edge always progresses to a static, single next edge. However, attached to this edge may be any number ofEdgeInstructions that manipulate the stack (see below).Node: A linear edge as well, this edge always progresses to a static, single next edge. However, attached to this edge is a task call that must be executed before continuing (see below).Stop: An edge that has no outgoing connector. Whenever this one is traversed, the driver simply stops executing the workflow and completes the interaction with the user.Branch: An edge that optionally takes one of two chains of edges (i.e., it has two outgoing connectors). Which of the two is taken depends on the current state of the stack.Parallel: An edge that has multiple outgoing connectors, but where all of those are taken concurrently. This edge is matches with aJoin-edge that merges the chains back together to one connector.Join: A counterpart to theParallelthat joins the concurrent streams of edges back into one outgoing connector. Doing so, the join may combine results coming from each branch in hardcoded, but configurable, ways.Loop: An edge that represents a conditional loop. Specifically, it has three connectors: one that points to a stream of edges for preparing the stack to analyse the condition at the start of every iteration; one that represents the edges that are repeatedly taken; and then one that is taken when the loop stops.Call: An edge that emulates a function call. While it is represented like a linear edge, first, a secondary body of edges is taken depending on the function identifier annotated to this edge. The driver only resumes traversing the outgoing connector once the secondary body hits aReturnedge.Return: An edge that lets a secondary function body return to the place where it was called from. Like function returns, this may manipulate the stack to push back function results.
Executing instructions
A few auxillary systems have to be in place, besides the stack, that is necessary for executing instructions.
First, the driver implements a frame stack as a separate entity from the stack itself. This defines where the driver should return to after every successive Call-edge, as well as any variables that are defined in that function body (such that they may be undeclared upon a return). Further, the framestack is also used to manage shadowing variable-, function- or type-declarations, as the current implementation does not do any name mangling.
Next, the driver also implements a variable register. This is used to keep track of values with a different lifetime from typical stack values, and that need to be stored temporarily during execution. Essentially, the variable register is a table of variable identifiers to values, where variables can be added (VarDec), removed (VarUndec), assigned new values (VarSet) or asked to provide their stored values (VarGet).
brane-plr: The planner
This chapter will be written soon.
brane-api: The global audit log
brane-job: The worker
brane-reg: The local audit log
brane-prx: The proxy
Introduction
Workflow Internal Representation
The Brane framework is designed to accept and run workflows, which are graph-like structures describing a particular set of tasks and how information flows between them. The Workflow Internal Representation (WIR) is the common representation that Brane receives from all its various frontends.
In these few chapters, the WIR is introduced and defined. For the remainder of this chapter, we will give context to the WIR about why it exists. In next chapters, we will then state its specification.
Two levels of workflow
Typically, we think of a workflow as a graph-like structure that contains only essential information about how to execute the tasks. Figure 1 shows an example of such a graph.

Figure 1: An example workflow graph. The node indicate a particular function, where the arrows indicate how data flows through them (i.e., it specifies data dependencies). Some nodes (i in this example), may influence the control flow dynamically to introduce branches or loops.
This is a very useful representation for policy interpretation, because policy tends to concern itself about data and how it flows. The typical workflow graph lends itself well to this kind of analysis, since reasoners can simply traverse the graph and analyse which task is executed where to see which sites may see their data or new datasets computed based on their data.
However, for Brane, this representation is incomplete. Due to its need to support scripting-like workflow languages, workflows have non-trivial control flow evaluation; for example, Brane workflows are not Directed A-cyclic Graphs (DAGs), since they may encode iterations, and control flow may depend on arbitrarily complex expressions defined only in the workflow file.
For example, if we take BraneScript as the workflow language, the user might express an intuitive workflow as seen in Listing 1. This workflow runs a particular task (train_alg()) conditionally, based on some loss that it returns. This is a typical example of a task that needs to run until it converges.
import ml_package;
let loss := 1.0;
let alg := init_alg();
while (loss < 1.0) {
alg := train_alg(alg);
loss := get_loss(alg);
}
Listing 1: Example snippet of BraneScript that shows a workflow with a conditional branch.
If we simply represent this as a graph of tasks with data-dependencies, the information on the condition part of the iteration gets lost: the graph does not tell us what to condition on or how to initialise the loss-variable (Figure 2). As such, the WIR has to represent also the control flow layer (Figure 3); and because this control flow can consist of multiple statements and arbitrarily complex expressions, this control flow layer needs describe a full layer of execution as well.

Figure 2: Graph representation of Listing 1 showing only the high-level aspects typically found in workflows. With only this information, the condition of the loop is non-obvious, as are its starting conditions.
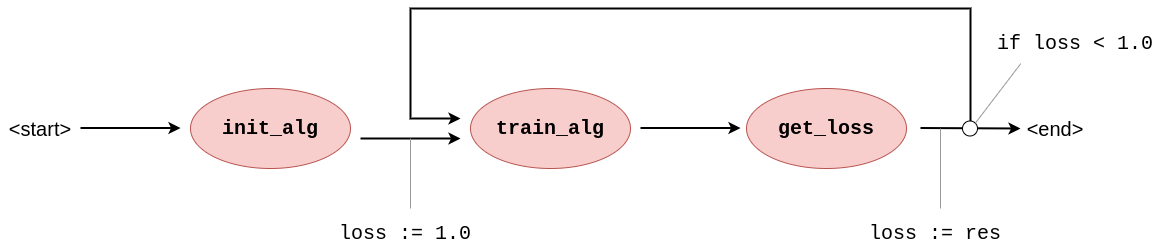
Figure 3: Graph representation of Listing 1 including the control flow annotations on its edges. Now, the workflow contains information on how to check the condition and update it every iteration.
In Brane, the WIR thus balances the requirements of the two services that interact with it:
- The
brane-drv-service prefers to represent a workflow imperatively, with statements performing some work "in-driver" (i.e., control flow execution) and some work "in-task" (such that it can touch sensitive data). - The checker-service, on the other hand, needs to learn about data dependencies and how data moves from location to location.
WIR to the rescue
As a solution to embed the two levels of execution, the WIR is structured very much like the graph in Figure 3, except that the annotations are encoded as stack instructions that pop values from- or push values to a stack in the runtime. Figure 4 shows a graph with such instructions.
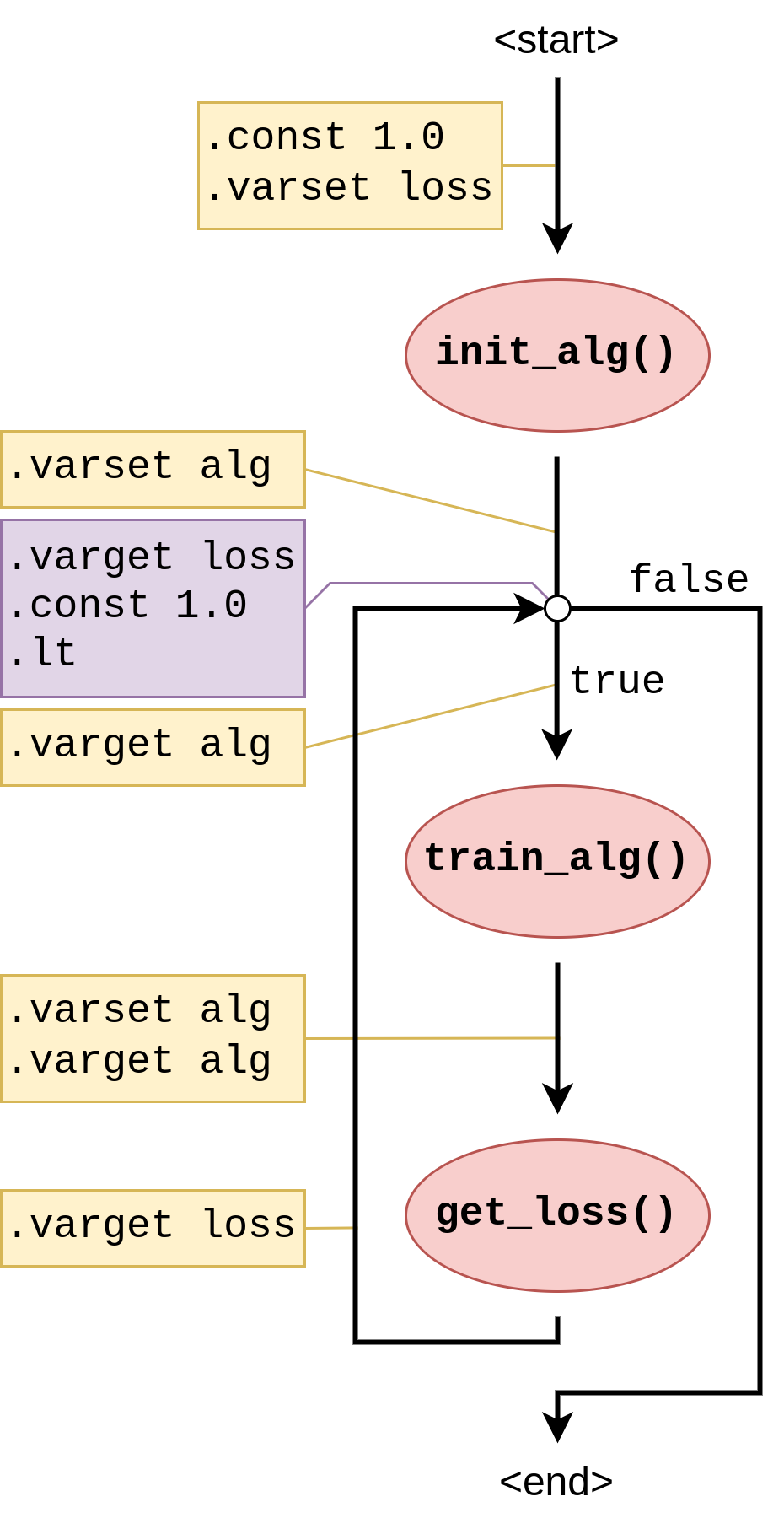
Figure 4: Graph representation of Listing 1 including WIR-instruction annotations on its edges. Now, an interpreter can follow the workflow's structure and execute the instructions as it goes, manipulating the stack as it goes until conditional control flow decisions are encountered that examine the current stack to make a decision.
At the toplevel, the WIR denotes a graph, where nodes represent task execution steps and edges represent transitions between them. To support parallel execution, branches, loops, etc, these edges can connect more than two nodes (or less, to represent start- or stop edges).
Then, these edges are annotated with edge instructions that are byte-like instructions encoding the control flow execution required to make conditional decisions. They manipulate a stack, and this stack then serves as input to either certain types of edges (e.g., a branch) or to tasks to allow them to portray conditional behaviour as well.
Functions
As an additional complexity, the WIR needs to have support for functions (since they are supported by BraneScript). Besides saving executable size by re-using code at different places in the execution, functions also allow for the use of specialised programming paradigms like recursion. Thus, the graph structure of the WIR needs to have a similar concept.
Functions in the WIR work similarly to functions in a procedural language. They can be thought of as snippets of the graph that are kept separately and can then be called using a special type of edges that transitions to the snippet graph first before continuing with its actual connection. This process is visualised in Figure 5.
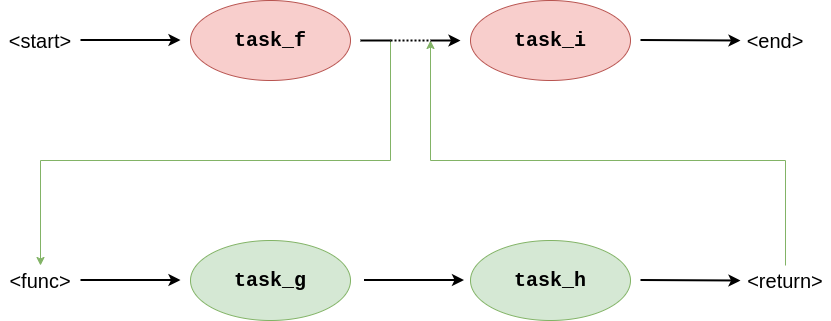
Figure 5: Graphs showing a "graph call", which is how the WIR represents function call. The edge connecting task_f to task_i implements the call by first executing the snippet task_g -> task_h before continuing to its original destination.
To emulate the full statement function, the edge also transfers some of the stack elements in the calling graph to the stack frame of the snippet graph. This way, arguments can be passed from one part of the graph to another to change its control flow as expected.
Next
In the next chapter, we introduce the toplevel structure of the WIR and how it is generally encoded. Then, in the next two chapters, we introduce the schemas for the graph structure, which can be thought of as the "higher-level layer" in the WIR, and the instructions, which can be thought of as the "lower-level layer" in the WIR.
If you are instead interested in how to execute a WIR-workflow, consult the documentation on the brane-drv-service. Analysing a WIR is for now done in the brane-plr-service only.
Toplevel schema
In this chapter, we will discuss specification for the toplevel part of the WIR. Its sub-parts, the graph representation and edge instructions, are discussed in subsequent chapters.
Regardless of which you read, we will start by stating a few conventions for how to read the specification. Then, this chapter will continue with the toplevel schema.
Conventions
For clarity, we specify the WIR as JSON. To refer to JSON types, we will use the terminology from the JSON Schema specification.
Note that the JSON representation of the WIR is implemented directly as Rust structs in the reference implementation. You can refer to the brane_ast-crate and then ast-module in the code documentation to find the full representation.
Finally, the use of the name Edge throughout this document is unfortunately chosen, as it represents more than edges. However, it is chosen to keep in sync with the implementation itself.
The Workflow
The toplevel structure in the WIR is the Workflow, which contains everything about the workflow it defines.
The workflow is a JSON Object, and contains the following fields:
table(SymTable): States the definitions of all toplevel functions, tasks, classes and variables. These definitions mostly contain information for type resolving; it does not contain function bodies. All definitions are mapped by identifier referred to in the graph.graph(Array<Edge>): A list ofEdges that defines the toplevel workflow. This is comparable to themain-function in C, and contains the edges executed first. The indices of the elements in this array are used as identifiers for the instructions.funcs(Object<number, Array<Edge>>): A map of function identifiers to nested arrays ofEdges. These can be called by the edges in the maingraph-or function bodies- to execute a particular snippet. The indices of the elements in the arrays are used as identifiers for the instructions.
Example Workflow:
TODO
The SymTable
The SymTable defines one of the fields of the toplevel Workflow, and contains information about the definitions used in the workflow. In particular, it gives type information for functions, classes and variables, and states what we need to know to perform an external task call for tasks. Finally, it also defines on which location particular intermediate results of a workflow may find themselves.
The following fields are present in a JSON Object representing a SymTable:
funcs(TableList<FunctionDef>): A list ofFunctionDefs that provide type information for a particular function. The indices of the elements in this array are used as identifiers for the definitions.tasks(TableList<TaskDef>): A list ofTaskDefs that provide information of tasks that we might execute. The indices of the elements in this array are used as identifiers for the definitions.classes(TableList<ClassDef>): A list ofClassDefs that provide information of tasks that we might execute. The indices of the elements in this array are used as identifiers for the definitions.vars(TableList<VarDef>): A list ofVarDefs that provide information of tasks that we might execute. The indices of the elements in this array are used as identifiers for the definitions.results(Object<string, string>): A map of identifiers of intermediate results to location names. This can be used by the planner or by checkers as a shortcut to find where the input of a particular task is coming from.
Example SymTable:
// An empty symbol table
{
"funcs": { "d": [], "o": 0 },
"tasks": { "d": [], "o": 0 },
"classes": { "d": [], "o": 0 },
"vars": { "d": [], "o": 0 },
"results": {},
}
// A table with some definitions
{
"funcs": { "d": [], "o": 0 },
"tasks": {
"d": [{
"kind": "cmp",
"p": "foo_package",
"v": "1.0.0",
"d": {
"n": "foo",
"a": [],
"r": { "kind": "void" },
"t": {
"funcs": { "d": [], "o": 0 },
"tasks": { "d": [], "o": 0 },
"classes": { "d": [], "o": 0 },
"vars": { "d": [], "o": 0 },
"results": {},
}
},
"a": [],
"r": { "kind": "void" }
}],
"o": 0
},
"classes": { "d": [], "o": 0 },
"vars": {
"d": [
{ "n": "foo", "t": { "kind": "str" } },
{ "n": "bar", "t": { "kind": "int" } }
],
"o": 0
},
"results": {},
}
// A table with some result locations
{
"funcs": { "d": [], "o": 0 },
"tasks": { "d": [], "o": 0 },
"classes": { "d": [], "o": 0 },
"vars": { "d": [], "o": 0 },
"results": {
"result_123": "hospital_a",
"result_456": "clinic_b",
},
}
The TableList
Generic parameter T
The TableList is a special kind of schema that defines a list with a particular offset. This is used to create a consistent scope of definitions, since one TableList can simply extend, or overlay parts of, another.
These fields are part of a TableList:
d(Array<T>): An array ofTs, which are the definitions contained within this TableList.o(number): The offset of this TableList in the parent list. This determines if this list simply extends or shadows part of the parent list.0implies it's the toplevel list.
For example, this defines a TableList over one FunctionDef without any offset:
{
"d": [{
"n": "foo",
"a": [],
"r": "void",
"t": {
"funcs": { "d": [], "o": 0 },
"tasks": { "d": [], "o": 0 },
"classes": { "d": [], "o": 0 },
"vars": { "d": [], "o": 0 },
"results": {},
}
}],
"o": 0
}
Or a TableList with multiple VarDefs and an offset:
{
"d": [
{
"n": "foo",
"t": { "kind": "str" }
},
{
"n": "bar",
"t": { "kind": "real" }
},
{
"n": "baz",
"t": { "kind": "arr", "t": { "kind": "int" } }
}
],
"o": 4
}
The FunctionDef
The FunctionDef defines the metadata of a particular function, like name and type information. In addition, it also contains definition present only in this function (e.g., local variables).
The following fields are part of the FunctionDef's specification:
n(string): The name of function.a(Array<DataType>): Defines the types of each of the arguments of the function, and also the function's arity as the length of this array. Further information, such as their names, can be found in the parameter's definition in thetable.r(DataType): States the return type of the function. If the function does not return anything, then this is aVoid-datatype.t(SymTable): The nestedSymTablethat states the definitions of all functions, tasks, classes and variables defined in this function.
Example FunctionDef:
// A minimum function `foo()`
{
"n": "foo",
"a": [],
"r": { "kind": "void" },
"t": {
"funcs": { "d": [], "o": 0 },
"tasks": { "d": [], "o": 0 },
"classes": { "d": [], "o": 0 },
"vars": { "d": [], "o": 0 },
"results": {},
}
}
// A function `bar(int, string) -> bool` with some type stuff
{
"n": "bar",
"a": [ { "kind": "int" }, { "kind": "str" } ],
"r": { "kind": "bool" },
"t": {
"funcs": { "d": [], "o": 0 },
"tasks": { "d": [], "o": 0 },
"classes": { "d": [], "o": 0 },
// This declares the arguments first
"vars": {
"d": [
{
"n": "some_arg",
"t": { "kind": "int" }
},
{
"n": "another_arg",
"t": { "kind": "str" }
},
],
"o": 0
},
"results": {},
}
}
// A function `baz() -> string` that defines a separate nested variable
{
"n": "baz",
"a": [],
"r": { "kind": "str" },
"t": {
"funcs": { "d": [], "o": 0 },
"tasks": { "d": [], "o": 0 },
"classes": { "d": [], "o": 0 },
"vars": {
"d": [{
"n": "var1",
"t": { "kind": "arr", "t": { "kind": "real" } }
}],
"o": 0
},
"results": {},
}
}
The TaskDef
The TaskDef describes all metadata of a task such that we can call it successfully.
There are two kinds of tasks:
Compute-tasks, which represent the execution of a container job; andTransfer-tasks, which represent a data transfer.

Transfertasks are actually not used by the reference implementation. They are here for legacy reasons and not removed because, at some point in the future, it may be nice if the planner may make transfers explicit.
The following fields are present regardless of the type of task:
kind(string): Determines the kind of theTaskDef. This can either be"cmp"forCompute, or"trf"forTransfer.
Then, for compute tasks, the following fields are added to this definition:
p(string): The name of the package in which the task is defined.v(Version): AVersionindicating the targeted version of the package in which the task is defined.d(FunctionDef): Defines the signature and name of the function such that we can execute it with type safety. It is guaranteed that thetable of the definition is empty, since the function does not have a body.a(Array<string>): Defines the names of every argument, since task arguments are named (present for better error experience). This array should be exactly as long as the array of arguments ind.r(Array<Capability>): A list of capabilities that any site executing this task needs to have. This is mostly used by the planner to restrict the sites it is considering.
Transfer tasks have no additional fields.
Examples of TaskDefs are:
// TaskDef without any arguments
{
"kind": "cmp",
"p": "foo_package",
"v": "1.0.0",
"d": {
"n": "foo",
"a": [],
"r": { "kind": "void" },
"t": {
"funcs": { "d": [], "o": 0 },
"tasks": { "d": [], "o": 0 },
"classes": { "d": [], "o": 0 },
"vars": { "d": [], "o": 0 },
"results": {},
}
},
"a": [],
"r": { "kind": "void" }
}
// TaskDef with some arguments
{
"kind": "cmp",
"p": "bar_package",
"v": "1.0.0",
"d": {
"n": "bar",
"a": [ { "kind": "bool" } ],
"r": { "kind": "void" },
// Always empty, regardless of arguments
"t": {
"funcs": { "d": [], "o": 0 },
"tasks": { "d": [], "o": 0 },
"classes": { "d": [], "o": 0 },
"vars": { "d": [], "o": 0 },
"results": {},
}
},
"a": [ "is_cool" ],
"r": { "kind": "void" }
}
The ClassDef
ClassDefs describe all metadata of a class such that we can create it, access its element and call its methods.
The following fields are found in a ClassDef:
n(string): The name of the class. This name is also used to resolveclssDataTypes.i(string?): The name of the package where this class was imported from or null if it was defined in BraneScript.v(Version?): The version of the package where this class was imported from or null if it was defined in BraneScript.p(Array<VarDef>): A list of properties of this class, given as variable definitions (since properties have a name and a data type too).m(Array<number>): A list of functions that are methods of thisClassDef. The functions are referred to by identifier, meaning their definition is given as a separateFunctionDef.
The following snippets showcase examples of ClassDefs:
// Represents class `Foo` that only has a few properties
{
"n": "Foo",
"i": null,
"v": null,
"p": [
{
"n": "prop1",
"t": { "kind": "str" }
},
{
"n": "prop2",
"t": { "kind": "int" }
},
],
"m": []
}
// Represents class `Bar` that has methods
{
"n": "Bar",
"i": null,
"v": null,
"p": [],
"m": [
{
"n": "method1",
// This argument essentially represents 'self'
"a": [ { "kind": "clss", "n": "Bar" } ],
"r": { "kind": "void" },
"t": {
"funcs": { "d": [], "o": 0 },
"tasks": { "d": [], "o": 0 },
"classes": { "d": [], "o": 0 },
"vars": { "d": [], "o": 0 },
"results": {},
}
}
]
}
// Represents class `Baz` that is imported but has otherwise nothing
{
"n": "Bar",
"i": "baz_package",
"v": "1.0.0",
"p": [],
"m": []
}
The VarDef
A variable's name and data type are described by a VarDef.
Accordingly, the following fields are found in the VarDef object:
n(string): The name of the variable.t(DataType): The data type of the variable.
The following are a few examples of valid VarDefs:
// A variable definition for `foo: string`
{
"n": "foo",
"t": { "kind": "str" }
}
// A variable definition for `bar: int[]`
{
"n": "bar",
"t": { "kind": "arr", "t": { "kind": "int" } }
}
// A variable definition for `baz: ExampleClass`
{
"n": "baz",
"t": { "kind": "clss", "n": "ExampleClass" }
}
Miscellaneous
The DataType
The DataType describes the kind of a value. This is typically used to propagate type information across a workflow.
A DataType can be of many variants. However, it always has at least the following fields:
kind(string): A string identifier differentiating between the possible variants. Possibilities are:"bool": Maps to a boolean type (i.e., a value that is eithertrueorfalse)."int": Maps to an integer type (i.e., a number without fraction)."real": Maps to a real type (i.e., a number with fraction)."str": Maps to a string type (i.e., a sequence of characters)."ver": Maps to a version number (i.e., a triplet of non-negative integers representing major, minor and patch version numbers)."arr": Maps to an array of some nested type (see below)."func": Maps to a function with a particular call signature (see below)."clss": Maps to a class (i.e., custom type) with a particular name (see below)."data": Maps to aDataobject."res": Maps to anIntermediateResultobject."any": Maps to any possible type. Used as a placeholder for types which the compiler cannot deduce at compile time."num": Maps to any numeric type (i.e., integers or reals)."add": Maps to any addable type (i.e., numerical types or strings)"call": Maps to any callable type (i.e., functions or methods)"nvd": Maps to any type that is not void."void": Maps to no type (i.e., no value).
Then some fields are added depending on the variant:
- For
"arr"-datatypes:t(DataType): The nested datatype of the elements of the array.
- For
"func"-datatypes:a(Array<DataType>): The datatypes of each of the arguments of the function. The length of the array simultaneously defines the function's arity.t(DataType): The return type of the function.
- For
"clss"-datatypes:n(string): The name of the class to which this data type is referring.
A few examples of DataTypes are:
// Strings
{
"kind": "str"
}
// Any type
{
"kind": "any"
}
// An array of numbers
{
"kind": "arr",
"t": {
"kind": "num"
},
}
// An array of arrays of strings
{
"kind": "arr",
"t": {
"kind": "arr",
"t": {
"kind": "str"
},
},
}
// A function call with two arguments, one return value
{
"kind": "func",
"a": [ { "kind": "int" }, { "kind": "str" } ],
"t": { "kind": "bool" }
}
// A class by the name of `Foo`
{
"kind": "clss",
"n": "Foo"
}
The Version
The Version is a string describing a version number. This is always a triplet of three numbers separated by commas. The first number represents the major version number; the second number represents the minor version number and the third number is the patch number.
The following regular expression may parse Versions:
[0-9]+\.[0-9]+\.[0-9]+
The Capability
A Capability is a string listing some kind of requirement on a compute site. This is used to sort them based on available hardware, compute power, etc.
Currently, the supported capabilities are:
"cuda_gpu": The compute site has a CUDA GPU available.
Layer 1: The graph
In this chapter, we specify how the part of the WIR looks like that specifies the high-level workflow graph.
The toplevel of the WIR itself, which mostly concerns itself with definitions, can be found in the previous chapter. By contrast, the next chapter defines the lower-level instructions that are used within edges of the graph.
We use the same conventions as in the previous chapter. We recommend you read them before continuing to understand what we wrote down.
Edges
Graphs in the WIR are built of segments called Edges. This is a misnamed term, because this represents both edges and nodes in the graph. The underlying idea, however, is that the graph is build up of edges of pre-defined shapes, like linear connectors, branches or loops, some of which happen to have a node attached to them.
The possible edge types are defined in the next few subsections. For every edge type, we will show an abstract representation of that edge. Here, the greyed-out, small spheres act as connectors that may be connected to connectors of other edges to build complex graph structures.
Specification-wise, all Edge variants have the following fields in common:
kind(string): Denotes which variant of theEdgethis object describes. The identifiers used are given below in each subsections.
Linear

Identifier: "lin"
The Linear edge is arguably the simplest edge. It simply connects to a single previous edge, and a single next edge. However, it is the only type of edge that can have arbitrary EdgeInstructions attached to it that manipulate the stack before the edge is traversed.
Concretely, a linear edge has the following fields:
i(Array<EdgeInstr>): A sequence of instructions to execute before traversing the edge.n(number): The index of the next edge to traverse.
The following is an example of a Linear edge:
TODO
Node
Identifier: "nod"
A Node edge is comparable to a Linear edge except that it executes a task instead of stack instructions. It connects a single previous edge to another next edge.
It has the following fields:
t(number): The identifier of the task's definition in the parentSymTable.l(Locations): Denotes where this task may be executed from the user's perspective (i.e., restricts planning).s(string?): Denotes where this task will actually be executed. Ifnull, then the planner failed and no possible location is found. Populated by the planner.i(Object<string,AvailabilityKind?>): A map of data/intermediate results identifiers to how they can be accessed (i.e., either where to find it locally or where to transfer it from). Note that the keys are serializedDataNameobjects. This effectively denotes the data used as input for this task.r(string?): The identifier of the intermediate result produced by this task (ornullif it does not produce any).n(number): The index of the next edge to traverse.
Example Node edge:
// Example Node edge that is unplanned
{
"kind": "nod",
"t": 5,
"l": "all",
"s": null,
"i": {
"{\"Data\":\"data_A\"}": null
"{\"IntermediateResult\":\"result_foo\"}": null
},
"r": "result_bar",
"n": 42
}
// Example Node edge that is planned
{
"kind": "nod",
"t": 5,
"l": "all",
"s": "hospital_A",
"i": {
"{\"Data\":\"data_A\"}": {
"kind": "available",
"how": {
"file": {
"path": "/data/data_A.txt"
}
}
},
"{\"IntermediateResult\":\"result_foo\"}": {
"kind": "unavailable",
"how": {
"transferregistrytar": {
"location": "hospital_B",
"address": "https://hospital_B.com/results/download/result_foo"
}
}
}
},
"r": "result_bar",
"n": 42
}
Stop

Identifier: "stp"
The Stop edge acts as the end of a workflow. The executing engine will stop traversing the graph as soon as this edge is traversed.
As such, the Stop-edge has no fields.
Example stop edge:
{
"kind": "stp"
}
Branch
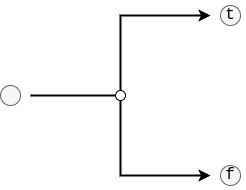
Identifier: "brc"
The Branch edge implements a conditional control flow branch. Based on the top value on the stack when this edge is traversed, one of either edges will be traversed next. As such, the top value should be a boolean and prepared by a Linear edge preceding this branch.
The fields that exist in the Branch:
t(number): The index of the edge to traverse if the top value on the stack is true.f(number?): The index of the edge to traverse if the top value on the stack is false. This value can benullif the user has a conditional branch with only a true-body. If so, then the edge denoted by them-field is executed when the top value is false.m(number?): The index of the edge where the true and false branches come together. This is useful for analysing the graph, as it allows one to skip the branch without recursing into it. Importantly, the merge edge is also used when the user did not define anf-branch. This value can only benullif there is a true- and false-branch, and both fully return (i.e., end in aStopedge).
An example Branch:
// An example branch that has a true and a false statement
{
"kind": "brc",
"t": 42,
"f": 52,
"m": 62
}
// An example branch that only has a true statement
{
"kind": "brc",
"t": 42,
"f": null,
"m": 62
}
// An example branch that has fully returning true- and false branches
{
"kind": "brc",
"t": 42,
"f": 52,
"m": null
}
Parallel
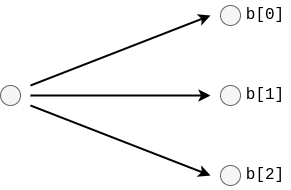
Identifier: "par"
Parallel edges are similar to branches in that they split a single sequence of edges into multiple. However, where a Branch forces a decision between one of the two sequences, the Parallel-edge denotes that the two (or more) can be taken simultaneously.
The counterpart of the Parallel-edge is the Join-edge, which marks where the parallel branches come together. The exact behaviour of this process is described when talking about the execution engine in the brane-drv service.
The Parallel edge has the following branches:
b(Array<number>): A list of indices pointing to the first edges in the branches.m(number): The index of theJoin-edge marking the end of this parallel branch. This is here to make analysing the graph easier and skipping the parallel without recursing into it.
An example of a parallel edge is:
// A parallel edge with two branches
{
"kind": "par",
"b": [ 42, 52 ],
"m": 62
}
Join
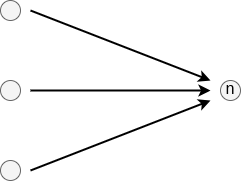
Identifier: "join"
The Join-edge is the counterpart to the Parallel-edge. Where the latter forks the sequence of edges into multiple edges that can be executed concurrently, the Join reverses this process and merges the forked sequences back to one. The exact behaviour of this process is described when talking about the execution engine in the brane-drv service.
It has the following fields:
m(MergeStrategy): Configures the behaviour of the join. In particular, states how to wait for the branches (if needed) and how to combine their resulting values.n(number): The index of the next edge to traverse.
The example of a Join-edge:
{
"kind": "join",
"m": "Sum",
"n": 42
}
Loop
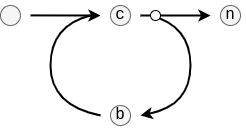
Identifier: "loop"
The Loop-edge connects to one sequence of edges that are taken repeatedly, and one sequence of edges that is taken once the condition completes.
Because the Loop is conditional, it depends on the top value on the stack every time at the start of a new iteration. In particular, this must be a boolean value, and the iteration is taken if it is true, and the next edge is taken if the value is false. Clearly, the loop body is allowed to manipulate the top of the stack in between checks.
The following fields are used in a Loop:
c(number): Defines the index of the first edge of a series that computes the condition at the start of every iteration.b(number): Defines the index of the first edge of a series that implements the body of the loop. These are the edges that are taken repeatedly as long as the edges ofccompute true.n(number): The index of the next edge to traverse once the edges ofccompute false.
An example Loop-edge is:
{
"kind": "loop",
"c": 42,
"b": 52,
"n": 62
}
Call
Identifier: "cll"
The Call-edge implements a call to another workflow snippet as if it were a function. In particular, before the next edge is traversed, a series of edges are executed until a Return-edge is traversed. This then unwinds the stack back to the point of the Call, possibly pushing a result of the function on there before continuing.
This edge thus behaves similarly to a Node-edge from the graph perspective, except that it calls other edges instead of a task container. Another difference is that the call does not inherently encode the function to call; instead, this is represented as a value on the stack and may thus differ dynamically to perform virtual function calls (although the rest of the language does not support this, currently).
The following fields make a Call:
n(number): The index of the next edge to traverse once the function body returns.
An example:
{
"kind": "cll",
"n": 42
}
Return

Identifier: "ret"
Counterpart to the Call-edge, the Return-edge marks the end of a function body. Doing so unwinds the stack until the state of the most recent Call, and possibly pushes the top value of the stack before unwinding after it's done (this emulates function return values).
The Return does not have any fields, since its behaviour is defined solely based on the stack and its frames.
Example Return:
{
"kind": "ret"
}
Miscellaneous
The Locations
The Locations object denotes possible locations given by a user for planning a task. Specifically, it has two variants: All, which means that no restriction is applied, or Restricted which defines a whitelist of allowed locations.
This schema can be one of either two things:
- It can be a string
"all"which denotes the first variant; or - It can be an Object with a key
"restricted"mapping to an Array<string> of location identifiers where the task is allowed.
Example Locations are:
// First variant
"all"
// Second variant, allowed nowhere
{
"restricted": []
}
// Second variant, allowed only at a limited set
{
"restricted": [ "hospital_A", "clinic_B" ]
}
The DataName
DataNames are objects that denote either the name of a Dataset or of an IntermediateResult.
As such, they are objects with exactly one of the following two fields:
Data(string): States the identifier of the dataset, and marks this as a Data by virtue of this field being present.IntermediateResult(string): States the identifier of the result, and marks this as an IntermediateResult by virtue of this field being present.
For example:
// A Data called `A`
{
"Data": "A"
}
// An IntermediateResult called 'result_B'
{
"IntermediateResult": "result_B"
}
The AvailabilityKind
An AvailabilityKind denotes how to get access to a particular dataset.
It has two variants: the Available-kind denotes that a domain has access to that dataset, and describes where it can find its own dataset. The Unavailable-variant instead describes which domain has access to the dataset and how to request that domain to download it.
The following fields are present for both variants:
kind(string): Denotes which variant this is. If it's"available", then the rest is of theAvailable-variant; otherwise, if it's"unavailable", then the rest is of theUnavailable-variant.
The Available-variant has the following additional fields:
h(AccessKind): Describes how to access the dataset for execution.
In contrast, the Unavailable-variant contains the following field:
h(PreprocessKind): Describes how to access a dataset for transferring.
For example:
// Available
{
"kind": "available",
"how": {
"file": {
"path": "/data/data_A.txt"
}
}
}
// Unavailable
{
"kind": "unavailable",
"how": {
"transferregistrytar": {
"location": "hospital_B",
"address": "https://hospital_B.com/results/download/result_foo"
}
}
}
The AccessKind
The AccessKind describes how a file can be accessed on the domain that uses it for execution. While it may have more variants in the future, for now it only supports the File-variant, which denotes that the dataset is a file.
The AccessKind is given as an object who's key denotes its variant. For File, this is the "file"-identifier. The mapped object contains the fields for that variant.
The File-variant has the following fields:
path(string): The path to the file to use.
For example:
// A File variant
{
"file": {
"path": "/hello/world.txt"
}
}
The PreprocessKind
The PreprocessKind describes how to gain access to a file for domains that don't have access yet. For now, only one variant exists, which is the TransferRegistryTar-variant: this means that the domain can download the dataset as a compressed tarball from a particular domain.
The PreprocessKind is given as an object who's key denotes its variant. For TransferRegistryTar, this is the "transferregistrytar"-identifier. The mapped object contains the fields for that variant.
The TransferRegistryTar-variant has the following fields:
location(string): The identifier of the domain to download the file from.address(string): The URL to send the HTTP-request to download the dataset file from.
Examples:
// A TransferRegistryTar variant
{
"transferregistrytar": {
"location": "hospital_A",
"address": "https://hospital_a.com/data/download/dataset_A"
}
}
The MergeStrategy
The MergeStrategy describes different ways how a Join can process the results of a Parallel branch.
It is defined as a string with one of the following possible values:
"First": The result of the first branch that returns is used, the rest of the branches are terminated if they are still running."FirstBlocking": The result of the first branch that returns is used, but the execution engine waits until all branches have completed before continuing."Last": The result of the last branch that returns is used."Sum": The values of all branches are added together. Only works if the return values are numerical (or strings!)."Product": The values of all branches are multiplied together. Only works if the return values are numerical."Max": The largest value of all return values is returned. Only works if the return values are numerical."Min": The smallest value of all return values is returned. Only works if the return values are numerical."All": All values of the branches are aggregated into an array of that type."None": The execution engine blocks until all branches have returned, but otherwise returns void.
Next
In the next chapter, we define the final parts of the WIR: the instructions that manipulate the stack and that can be annotated on a Linear-edge. If you are reading the WIR bottom-up, you should instead proceed to the previous chapter where we define the toplevel of the WIR, which mostly relates to definitions and how edges are tied together.
Alternatively, you can select a different topic than the WIR altogether in the sidebar on the left.
Layer 2: Instructions
This chapter looks at the lowest level of the WIR, which implements a simply assembly-like instruction language for manipulating the stack that determines the graph control flow.
The edges of the graph themselves are defined in the previous chapter, and the chapter before that talks about the toplevel of the WIR representation tying the edges together.
We use the same conventions as in the previous chapters. We recommend you read them before continuing to understand what we wrote down.
EdgeInstrs
A Linear-edge may be annotated with zero or more EdgeInstructions, which are assembly-like instructions that manipulate a workflow-wide stack. Some Edges manipulate the stack too, most often reading from it, but most work is done by explicitly stating the instructions.
As discussed in the introduction chapter, the instructions essentially implement a second layer of computation. Where the edges mostly related to "on-graph" computation, the edge instructions can be thought of as "off-graph" computation that typically matters less for reasoners.
As far as the specification goes, the the following fields are shared by all instructions:
kind(string): Denotes which variant of theEdgeInstrthis object describes. The identifiers used are given below in each subsections.
A convenient index of all instructions:
Cast: Casts a value to another type.Pop: Discards the top value on the stack.PopMarker: Pushes an invisible value that is used by...DynamicPop: Pops values off the stack until the invisible value pushed byPopMarkeris popped.Branch: Conditionally jumps to another instruction within the same stream.BranchNot: Conditionally jumps to another instruction within the same stream but negated.Not: Performs logical negation.Neg: Performs arithmetic negation.And: Performs logical conjunction.Or: Performs logical disjunction.Add: Performs arithmetic addition / string concatenation.Sub: Performs arithmetic subtraction.Mul: Performs arithmetic multiplication.Div: Performs arithmetic division.Mod: Performs arithmetic modulo.Eq: Compares two values.Ne: Compares two values but negated.Lt: Compares two numerical values in a less-than fashion.Le: Compares two numerical values in a less-than-or-equal-to fashion.Gt: Compares two numerical values in a greater-than fashion.Ge: Compares two numerical values in a greater-than-or-equal-to fashion.Array: Pushes an array literal onto the stack (or rather, creates one out of existing values).ArrayIndex: Takes an array and an index and pushes the element of the array at that index.Instance: Pushes a new instance of a class onto the stack by popping existing values.Proj: Projects a field on an instance to get that field's value.VarDec: Declares the existance of a variable.VarUndec: Releases the resources of a variable.VarGet: Gets the value of a variable.VarSet: Sets the value of a variable.Boolean: Pushes a boolean constant.Integer: Pushes a integer constant.Real: Pushes a floating-point constant.String: Pushes a string constant.Function: Pushes a function handle on top of the stack.
Cast
Identifier: "cst"
The Cast takes the top value off the stack and attempts to perform a type conversion on it. Then, the result is pushed back on top of the stack.
Specification-wise, the Cast needs one additional field:
t(DataType): Defines the datatype the top value on the stack to.
Stack-wise, the Cast manipulates the stack in the following way:
- pops
DataType::Anyfrom the stack; and - pushes An object of type
ton top of the stack representing the same value but as another type.
Note that this conversion may fail, since not all types can be converted into other types. Specifically, the following convertions are defined, where T and U represent arbitrary types and Ts and Us represents lists of arbitrary, possibly heterogenously typed values:
booltointcreates a 1 if the input value is true or a 0 otherwise.booltostrcreates a "true" if the input value is true, or a "false" if the input value is false.inttoboolcreates true if the input value is non-zero, or false otherwise.inttorealcreates an equivalent floating-point number.inttostrwrites the integer as a serialized number.realtointwrites the floating-point value rounded down to the nearest integer.realtostrwrites the floating-point number as a serialized number.arr<T>tostrcasts the elements in the array fromTtostrand then serializes them within square brackets ([]), separated by comma's (,) (e.g.,"[ 42, 43, 44 ]").arr<T>toarr<U>casts every element in the array fromTtoU.func(Ts) -> Ttofunc(Us) -> Uis a no-op but only ifTs == UsandT == U.func(Ts) -> Ttostrcasts the values inTstostrandTtostrand then writes the name of the function followed by the arguments in parenthesis (()) followed by->and the return type (e.g.,"foo(int, real) -> str"). If the function is a class method, then the class name and::are prefixed to the function name (e.g.,Foo::foo(Foo, int, real) -> str).func(Ts) -> Ttoclssis a no-op, even keeping the same type, but only if the function is a method and belongs to the class it is casted to. This can be used to assert that a method is part of a class(?).clss<Ts>tostrcasts the values inTstostrand then serializes it as the class name followed by the values in the class serialized as name:=value separated by comma's in between curly brackets ({}) (e.g.,Foo { foo := 42, bar := "test" }).DatatostrwritesData, and then the name of the data in triangular brackets (<>) (e.g.,"Data<Foo>").DatatoIntermediateResultis a no-op.IntermediateResulttostrwritesIntermediateResult, and then the name of the data in triangular brackets (<>) (e.g.,"IntermediateResult<Foo>").TtoTperforms a no-op.TtoAnyperforms a no-op and just changes the type.
Any convertion not mentioned here is defined to be illegal.
As such, the Cast can throw the following errors:
Empty stackwhen popping;Stack overflowwhen pushing; orIllegal castwhen the value cannot be casted to typet.
The following is an example Cast-instruction:
{
"kind": "cst",
"t": "str"
}
Pop
Identifier: "pop"
Pops the top value off the stack and discards it.
This instruction does not require any additional fields.
Stack-wise, the Pop does the following:
- pops
DataType::Anyfrom the stack.
It may throw the following error:
Empty stackwhen popping.
An example:
{
"kind": "pop"
}
PopMarker
Identifier: "mpp"
Pushes a so-called pop marker onto the stack, which can then be popped using the DynamicPop-instruction. This combination can be used when popping an unknown number of values off the stack.
This instruction does not require any additional fields.
Stack-wise, the PopMarker does the following:
- pushes a special value onto the stack that is invisible to most operations except
DynamicPop.
It may throw the following error:
Stack overflowwhen pushing.
An example:
{
"kind": "mpp"
}
DynamicPop
Identifier: "dpp"
Dynamically pops the stack until a PopMarker is popped. This combination can be used when popping an unknown number of values off the stack.
This instruction does not require any additional fields.
Stack-wise, the PopMarker does the following:
- pops a dynamic amount of values off the stack until
PopMarker's special value is popped.
Doing so may make it throw the following error:
Empty stackwhen popping.
An example:
{
"kind": "dpp"
}
Branch
Identifier: "brc"
Not to be confused with the Branch-edge, this instruction implements a branch in the instruction stream only. This is only allowed when it's possible to do this within the same linear edge, implying the branch does not influence directly which nodes are executed.
The branch is taken when the top value on the stack is true; otherwise, it is ignored and implements a no-op.
The Branch defines the following fields:
n(number): The relative offset to jump to. This can be thought of as "number of instructions to skip", where a value of -1 points to the previous instruction, 0 points to theBranch-instruction itself and 1 points to the next instruction.
Stack-wise, the Branch does the following:
- pops
DataType::Booleanfrom the stack.
As such, it can throw the following errors:
Empty stackwhen popping; orType errorwhen the popped value is not abool.
Note that skipping outside of the sequence of instructions belonging to a Linear-edge means the VM simply stops executing.
An example Branch-instruction:
{
"kind": "brc",
"n": 5
}
BranchNot
Identifier: "brn"
Counterpart to the Branch-instruction that behaves the same except that it branches when the value on the stack is false instead of true.
The BranchNot defines the following fields:
n(number): The relative offset to jump to. This can be thought of as "number of instructions to skip", where a value of -1 points to the previous instruction, 0 points to theBranchNot-instruction itself and 1 points to the next instruction.
Stack-wise, the Branch does the following:
- pops
DataType::Booleanfrom the stack.
As such, it can throw the following errors:
Empty stackwhen popping; orType errorwhen the popped value is not abool.
Note that skipping outside of the sequence of instructions belonging to a Linear-edge means the VM simply stops executing.
An example Branch-instruction:
{
"kind": "brn",
"n": 5
}
Not
Identifier: "not"
Implements a logical negation on the top value on the stack.
The Not does not need additional fields to do this.
Stack-wise, the Not does the following:
- pops
DataType::Booleanfrom the stack; and - pushes
DataType::Booleanon top of the stack.
As such, it can throw the following errors:
Empty stackwhen popping;Type errorwhen the popped value is not abool; orStack overflowwhen pushing.
Example:
{
"kind": "not"
}
Neg
Identifier: "neg"
Implements a arithmetic negation on the top value on the stack.
The Neg does not need additional fields to do this.
Stack-wise, the Neg does the following:
- pops
DataType::Numericfrom the stack; and - pushes
DataType::Numericon top of the stack.
As such, it can throw the following errors:
Empty stackwhen popping;Type errorwhen the popped value is not anintorreal; orStack overflowwhen pushing.
Example:
{
"kind": "neg"
}
And
Identifier: "and"
Performs logical conjunction on the top two values on the stack.
No additional fields are needed to do this.
Stack-wise, the And does the following:
- pops
DataType::Booleanfor the righthand-side; - pops
DataType::Booleanfor the lefthand-side; and - pushes
DataType::Booleanthat is the conjunction of the LHS and RHS.
The following errors can occur during this process:
Empty stackwhen popping;Type errorwhen the popped values are not abool; orStack overflowwhen pushing.
Example:
{
"kind": "and"
}
Or
Identifier: "or"
Performs logical disjunction on the top two values on the stack.
No additional fields are needed to do this.
Stack-wise, the Or does the following:
- pops
DataType::Booleanfor the righthand-side; - pops
DataType::Booleanfor the lefthand-side; and - pushes
DataType::Booleanthat is the disjunction of the LHS and RHS.
The following errors can occur during this process:
Empty stackwhen popping;Type errorwhen the popped values are not abool; orStack overflowwhen pushing.
Example:
{
"kind": "or"
}
Add
Identifier: "add"
Performs arithmetic addition or string concatenation on the top two values on the stack. Which of the two depends on the types of the popped values.
The Add does not introduce additional fields.
Stack-wise, the Add does the following:
- pops
DataType::Integer,DataType::RealorDataType::Stringfor the righthand-side; - pops
DataType::Integer,DataType::RealorDataType::Stringfor the lefthand-side; and - pushes
DataType::Integer,DataType::RealorDataType::Stringdepending on the input types:- If both arguments are
DataType::Integer, then a new integer is pushed that is the arithmetic addition of the LHS and RHS; - If both arguments are
DataType::Real, then a new real is pushed that is the arithmetic addition of both the LHS and RHS; and - If both arguments are
DataType::String, then a new string is pushed that is the concatenation of the LHS and then the RHS.
- If both arguments are
The following errors may occur when processing an Add:
Empty stackwhen popping;Type errorwhen the popped values do not match any of the three cases above;Overflow errorwhen the addition results in integer/real addition; orStack overflowwhen pushing.
Example:
{
"kind": "add"
}
Sub
Identifier: "sub"
Performs arithmetic subtraction on the top two values on the stack.
The Sub does not introduce additional fields.
Stack-wise, the Sub does the following:
- pops
DataType::IntegerorDataType::Realfor the righthand-side; - pops
DataType::IntegerorDataType::Realfor the lefthand-side; and - pushes
DataType::IntegerorDataType::Realdepending on the input types:- If both arguments are
DataType::Integer, then a new integer is pushed that is the arithmetic subtraction of the LHS and RHS; and - If both arguments are
DataType::Real, then a new real is pushed that is the arithmetic subtraction of both the LHS and RHS.
- If both arguments are
The following errors may occur when processing an Add:
Empty stackwhen popping;Type errorwhen the popped values do not match any of the two cases above;Overflow errorwhen the subtraction results in integer/real underflow; orStack overflowwhen pushing.
Example:
{
"kind": "sub"
}
Mul
Identifier: "mul"
Performs arithmetic multiplication on the top two values on the stack.
The Mul does not introduce additional fields.
Stack-wise, the Mul does the following:
- pops
DataType::IntegerorDataType::Realfor the righthand-side; - pops
DataType::IntegerorDataType::Realfor the lefthand-side; and - pushes
DataType::IntegerorDataType::Realdepending on the input types:- If both arguments are
DataType::Integer, then a new integer is pushed that is the arithmetic multiplication of the LHS and RHS; and - If both arguments are
DataType::Real, then a new real is pushed that is the arithmetic multiplication of both the LHS and RHS.
- If both arguments are
The following errors may occur when processing an Add:
Empty stackwhen popping;Type errorwhen the popped values do not match any of the two cases above;Overflow errorwhen the multiplication results in integer/real overflow; orStack overflowwhen pushing.
Example:
{
"kind": "mul"
}
Div
Identifier: "div"
Performs arithmetic division on the top two values on the stack.
The Div does not introduce additional fields.
Stack-wise, the Div does the following:
- pops
DataType::IntegerorDataType::Realfor the righthand-side; - pops
DataType::IntegerorDataType::Realfor the lefthand-side; and - pushes
DataType::IntegerorDataType::Realdepending on the input types:- If both arguments are
DataType::Integer, then a new integer is pushed that is the integer division of the LHS and RHS (i.e., rounded down to the nearest integer); and - If both arguments are
DataType::Real, then a new real is pushed that is the floating-point division of both the LHS and RHS.
- If both arguments are
The following errors may occur when processing an Add:
Empty stackwhen popping;Type errorwhen the popped values do not match any of the two cases above;Overflow errorwhen the division results in real underflow; orStack overflowwhen pushing.
Example:
{
"kind": "div"
}
Mod
Identifier: "mod"
Computes the remainder of dividing one value on top of the stack with another.
The Mod does not introduce additional fields to do so.
Stack-wise, the Mod does the following:
- pops
DataType::Integerfor the righthand-side; - pops
DataType::Integerfor the lefthand-side; and - pushes
DataType::Integerthat is the remainder of dividing the LHS by the RHS.
The following errors may occur when processing a Mod:
Empty stackwhen popping;Type errorwhen the popped values are notints; orStack overflowwhen pushing.
Example:
{
"kind": "mod"
}
Eq
Identifier: "eq"
Compares the top two values on the stack for equality. This is first type-wise (their types must be equal), and then value-wise.
No additional fields are introduced to do so.
Stack-wise, the Eq does the following:
- pops
DataType::Anyfor the righthand-side; - pops
DataType::Anyfor the lefthand-side; and - pushes
DataType::Booleanwith true if the LHS equals the RHS, or false otherwise.
The following errors may occur when processing an Eq:
Empty stackwhen popping; orStack overflowwhen pushing.
Example:
{
"kind": "eq"
}
Ne
Identifier: "ne"
Compares the top two values on the stack for inequality. This is first type-wise (their types must be unequal), and then value-wise.
No additional fields are introduced to do so.
Stack-wise, the Ne does the following:
- pops
DataType::Anyfor the righthand-side; - pops
DataType::Anyfor the lefthand-side; and - pushes
DataType::Booleanwith true if the LHS does not equal the RHS, or false otherwise.
The following errors may occur when processing an Eq:
Empty stackwhen popping; orStack overflowwhen pushing.
Example:
{
"kind": "ne"
}
Lt
Identifier: "lt"
Compares the top two values on the stack for order, specifically less-than. This can only be done for numerical values.
No additional fields are introduced to do so.
Stack-wise, the Lt does the following:
- pops
DataType::Numericfor the righthand-side; - pops
DataType::Numericfor the lefthand-side; and - pushes
DataType::Booleanwith true if the LHS is stricly less than the RHS, or false otherwise.
The following errors may occur when processing an Lt:
Empty stackwhen popping;Type errorwhen either argument is not anumor they are not of the same type (i.e., cannot compareintwithreal); orStack overflowwhen pushing.
Example:
{
"kind": "lt"
}
Le
Identifier: "le"
Compares the top two values on the stack for order, specifically less-than-or-equal-to. This can only be done for numerical values.
No additional fields are introduced to do so.
Stack-wise, the Le does the following:
- pops
DataType::Numericfor the righthand-side; - pops
DataType::Numericfor the lefthand-side; and - pushes
DataType::Booleanwith true if the LHS is less than or equal to the RHS, or false otherwise.
The following errors may occur when processing an Le:
Empty stackwhen popping;Type errorwhen either argument is not anumor they are not of the same type (i.e., cannot compareintwithreal); orStack overflowwhen pushing.
Example:
{
"kind": "le"
}
Gt
Identifier: "gt"
Compares the top two values on the stack for order, specifically greater-than. This can only be done for numerical values.
No additional fields are introduced to do so.
Stack-wise, the Gt does the following:
- pops
DataType::Numericfor the righthand-side; - pops
DataType::Numericfor the lefthand-side; and - pushes
DataType::Booleanwith true if the LHS is strictly greater than to the RHS, or false otherwise.
The following errors may occur when processing an Gt:
Empty stackwhen popping;Type errorwhen either argument is not anumor they are not of the same type (i.e., cannot compareintwithreal); orStack overflowwhen pushing.
Example:
{
"kind": "gt"
}
Ge
Identifier: "ge"
Compares the top two values on the stack for order, specifically greater-than-or-equal-to. This can only be done for numerical values.
No additional fields are introduced to do so.
Stack-wise, the Ge does the following:
- pops
DataType::Numericfor the righthand-side; - pops
DataType::Numericfor the lefthand-side; and - pushes
DataType::Booleanwith true if the LHS is greater than or equal to the RHS, or false otherwise.
The following errors may occur when processing an Ge:
Empty stackwhen popping;Type errorwhen either argument is not anumor they are not of the same type (i.e., cannot compareintwithreal); orStack overflowwhen pushing.
Example:
{
"kind": "ge"
}
Array
Identifier: "arr"
Consumes a number of values from the top off the stack and creates a new Array with them.
The Array specifies the following additional fields:
l(number): The number of elements to pop, i.e., the length of the array.t(DataType): The data type of the array. Note that this includes thearrdatatype and its element type.
Stack-wise, the Array does the following:
- pops
lvalues of typet; and - pushes
DataType::Arraywithlelements of typet. Note that the order of elements is reversed (i.e., the first element popped is the last element of the array).
Doing so may trigger the following errors:
Empty stackwhen popping;Type errorwhen a popped value does not have typet; orStack overflowwhen pushing.
Example:
// Represents an array literal of length 5, element type `str`
{
"kind": "arr",
"l": 5,
"t": { "kind": "arr", "t": { "kind": "str" } }
}
ArrayIndex
Identifier: "arx"
Indexes an array value on top of the stack with some index and outputs the element at that index.
The ArrayIndex specifies the following additional fields:
t(DataType): The data type of the element. This is the type of the pushed value.
Stack-wise, the ArrayIndex does the following:
- pops
DataType::Integerfor the index; - pops
DataType::Arrayfor the array to index, which must have element typet; and - pushes a value of type
tthat is the element at the specified index.
Doing so may trigger the following errors:
Empty stackwhen popping;Type errorwhen any of the popped values are incorrectly typed;Array out-of-boundswhen the index is too large for the given array, or if it's negative; orStack overflowwhen pushing.
Example:
/// Indexes an array of string elements
{
"kind": "arx",
"t": { "kind": "str" }
}
Instance
Identifier: "ins"
Consumes a number of values on top of the stack in order to construct a new instance of a class.
To do so, the Instance defines additional fields:
d(number): Identifier of the type which we are constructing. This definition is given in the parent symbol table.
Stack-wise, the Instance does the following:
- pops
Nvalues of varying types from the top off the stack, whereNis the number of fields (which may be 0) and the types are those matching to the fields. Note that they are popped in reverse alphabetical order, e.g., fieldais below fieldzon the stack; and - pushes a value of the type referred to by
d.
Doing so may trigger the following errors:
Unknown definitionifdis not known in the symbol tables;Empty stackwhen popping;Type errorwhen any of the popped values are incorrectly typed; orStack overflowwhen pushing.
Example:
{
"kind": "ins",
"d": 42
}
Proj
Identifier: "prj"
The Proj instruction takes an instance and retrieves the value of the given field from it.
The field is embedded in the instruction. As such, it adds the following specification fields:
f(string): The name of the field to project.
Stack-wise, the Proj does the following:
- pops an instance value; and
- pushes the value of field
fin that instance.
The projection ducktypes the instance, and as such can trigger the following errors:
Empty stackwhen popping;Unknown fieldwhen the popped instance has no field by the name described inf; orStack overflowwhen pushing.
Example:
{
"kind": "prj",
"f": "foo"
}
VarDec
Identifier: "vrd"
Declares a new variable, giving an opportunity to the underlying execution context to reserve space for it.
The following fields are added by a VarDec:
d(number): The identifier of the variable definition in the parent symbol table of the variable we're declaring. Note that, because definitions are scoped to functions, this is a unique identifier for specific variable instances the current scope.
Stack-wise, the VarDec doesn't do anything, as it fully acts on the underlying variable system.
The following errors may occur when working with the VarDec:
Unknown definitionifdis not known in the symbol tables; orVariable errorif the underlying context finds another reason to crash.
Example:
{
"kind": "vrd",
"d": 42
}
VarUndec
Identifier: "vru"
Explicitly undeclares a new variable, giving an opportunity to the underlying execution context to claim back space for it.
The following fields are added by a VarUndec:
d(number): The identifier of the variable definition in the parent symbol table of the variable we're undeclaring.Note that, because definitions are scoped to functions, this is a unique identifier for specific variable instances the current scope.
Stack-wise, the VarUndec doesn't do anything, as it fully acts on the underlying variable system.
The following errors may occur when working with the VarUndec:
Unknown definitionifdis not known in the symbol tables; orVariable errorif the underlying context finds another reason to crash.
Example:
{
"kind": "vru",
"d": 42
}
VarGet
Identifier: "vrg"
Retrieves the value of a variable which was previously VarSet.
The following fields are added by a VarGet:
d(number): The identifier of the variable definition in the parent symbol table of the variable we're undeclaring.Note that, because definitions are scoped to functions, this is a unique identifier for specific variable instances the current scope.
Stack-wise, the VarGet does the following:
- pushes the value stored in the variable on top of the stack.
The following errors may occur when working with the VarGet:
Unknown definitionifdis not known in the symbol tables;Variable errorif the underlying context finds another reason to crash; orStack overflowwhen pushing.
Example:
{
"kind": "vrs",
"d": 42
}
VarSet
Identifier: "vrs"
Moves the value on top of the stack to a variable so it may be VarGet.
The following fields are added by a VarSet:
d(number): The identifier of the variable definition in the parent symbol table of the variable we're undeclaring.Note that, because definitions are scoped to functions, this is a unique identifier for specific variable instances the current scope.
Stack-wise the VarSet does the following:
- pops
DataType::Anyfrom the stack to put in the variable.
The following errors may occur when working with the VarGet:
Unknown definitionifdis not known in the symbol tables;Variable errorif the underlying context finds another reason to crash;Empty stackwhen popping; orType errorwhen the type of the popped value does not match the type of the variable.
Example:
{
"kind": "vrs",
"d": 42
}
Boolean
Identifier: "bol"
Pushes a boolean constant on top of the stack.
The following fields are added by a Boolean:
v(bool): The boolean value to push.
Stack-wise, the Boolean does the following:
- pushes
DataType::Booleanon top of the stack.
The following errors may occur when executing a Boolean:
Stack overflowwhen pushing.
Example:
{
"kind": "bol",
"v": true
}
Integer
Identifier: "int"
Pushes an integer constant on top of the stack.
The following fields are added by a Integer:
v(number): The integer value to push.
Stack-wise, the Integer does the following:
- pushes
DataType::Integeron top of the stack.
The following errors may occur when executing a Integer:
Stack overflowwhen pushing.
Example:
{
"kind": "int",
"v": -84
}
Real
Identifier: "rel"
Pushes a floating-point constant on top of the stack.
The following fields are added by a Real:
v(number): The floating-point value to push.
Stack-wise, the Real does the following:
- pushes
DataType::Realon top of the stack.
The following errors may occur when executing a Real:
Stack overflowwhen pushing.
Example:
{
"kind": "rel",
"v": 0.42
}
String
Identifier: "str"
Pushes a string constant on top of the stack.
The following fields are added by a String:
v(string): The string value to push.
Stack-wise, the String does the following:
- pushes
DataType::Stringon top of the stack.
The following errors may occur when executing a String:
Stack overflowwhen pushing.
Example:
{
"kind": "str",
"v": "Hello, world!"
}
Function
Identifier: "fnc"
Pushes a function handle on top of the stack so it may be called.
The following fields are added by a Function:
d(number): The ID of the function definition which to push on top of the stack.
Stack-wise, the Function does the following:
- pushes
DataType::Functionon top of the stack.
The following errors may occur when executing a Function:
Unknown definitionifdis not known in the symbol tables; orStack overflowwhen pushing.
Example:
{
"kind": "fnc",
"v": 42
}
Next
This chapter concludes the specification of the WIR.
If you are intending to discover the WIR bottom-up, continue to the previous chapter to see how the graph overlaying the instructions is represented.
Otherwise, you can learn other aspects of the framework or the specification by selecting a different topic in the sidebar on the left.
Introduction
This series of chapters reports on thoughts on the future work that is not yet implemented in Brane.
The chapters form separate ideas that are discussed in isolation. You can select one from the list below or in the sidebar to the left:
- Reasoner extensions
- TODO
Appendix A: BraneScript specification
Brane is designed to be loosely-coupled between how scientists interact with it and how the framework receives its input (see Design requirements). As such, the framework specification itself only specifies the Workflow Internal Representation (WIR), which unifies all frontends into one language.
That said, the framework does feature its own workflow language, BraneScript. These chapters are dedicated to documenting the language. To learn how to use the language, refer to The User Guide instead.
Background
BraneScript is originally designed as a counterpart to Bakery, a workflow language that featured natural-language-like syntax for better compatability with domain scientists who do not have any programming experience. BraneScript was designed as a more developer-friendly counterpart, and eventually became the predominantly used language for the framework.
BraneScript is a compiled language, meaning that the frontend of the framework reads the submitted files and translates them to another representation before execution (specifically, Brane's WIR). Because it is compiled, this gives the opportunity for the compiler to perform checks and analysis before accepting the program or not, allow it to catch programmer mistakes early.
A downside of compilation is that it plays less nice with Brane's Read-Eval-Print Loop (REPL). The REPL is a feature of the brane-executable that allows a workflow to be defined step-by-step, interleaving execution and definition. For example, it means that submitting an entire program
import hello_world();
let test1 := hello_world();
println(hello_world());
as one file must give the same result as submitting
import hello_world();
let test1 := hello_world();
println(hello_world());
as three separate snippets within the same REPL-session.
To support this, the BraneScript compiler has a notion of compile state that is kept in between compilation runs. This complicates the compilation process, as can be seen through the chapters in this series.
Layout
The chapters are structured as follows. First, in the Features-chapter, we discuss the concepts of the language and which statements exist. Then, we examine particulars of the language: the grammar, scoping rules, typing rules, workflow analysis and concrete compilation steps.
Finally, in the Future work-chapter, we elaborate on ideas and improvements not yet implemented.
Appendix A: BraneScript specification
Brane is designed to be loosely-coupled between how scientists interact with it and how the framework receives its input (see Design requirements). As such, the framework specification itself only specifies the Workflow Internal Representation (WIR), which unifies all frontends into one language.
That said, the framework does feature its own workflow language, BraneScript. These chapters are dedicated to documenting the language. To learn how to use the language, refer to The User Guide instead.
Background
BraneScript is originally designed as a counterpart to Bakery, a workflow language that featured natural-language-like syntax for better compatability with domain scientists who do not have any programming experience. BraneScript was designed as a more developer-friendly counterpart, and eventually became the predominantly used language for the framework.
BraneScript is a compiled language, meaning that the frontend of the framework reads the submitted files and translates them to another representation before execution (specifically, Brane's WIR). Because it is compiled, this gives the opportunity for the compiler to perform checks and analysis before accepting the program or not, allow it to catch programmer mistakes early.
A downside of compilation is that it plays less nice with Brane's Read-Eval-Print Loop (REPL). The REPL is a feature of the brane-executable that allows a workflow to be defined step-by-step, interleaving execution and definition. For example, it means that submitting an entire program
import hello_world();
let test1 := hello_world();
println(hello_world());
as one file must give the same result as submitting
import hello_world();
let test1 := hello_world();
println(hello_world());
as three separate snippets within the same REPL-session.
To support this, the BraneScript compiler has a notion of compile state that is kept in between compilation runs. This complicates the compilation process, as can be seen through the chapters in this series.
Layout
The chapters are structured as follows. First, in the Features-chapter, we discuss the concepts of the language and which statements exist. Then, we examine particulars of the language: the grammar, scoping rules, typing rules, workflow analysis and concrete compilation steps.
Finally, in the Future work-chapter, we elaborate on ideas and improvements not yet implemented.
Features
In this chapter, we explain BraneScript from a user experience perspective. We go over the main design choices and language concepts it features to understand what the rest of this appendix is working towards.
If you are already familiar with BraneScript as a user and want to learn how to parse it, refer to the Formal grammar chapter; if you are instead interesting in compiling the resulting AST to the Workflow Intermediate Representation (WIR), refer to the subsequent chapters instead.
BraneScript: A scripting-like language
Primarily, BraneScript is designed to emulate a scripting-like language for defining workflows. As such, it is not approximating a graph structure, as workflows are typically represented, but instead defines a series of statements and expressions that can arbitrarily call external tasks. This means the language is very similar in usage as Lua or Python, "unfolding" to a workflow more than directly encoding it. Listing 1 shows an example BraneScript snippet.
// Import a package that defines external tasks
import hello_world;
// Print some text running it on a particular location!
#[on("site_1")]
{
println("A message has come in:");
println(hello_world());
}
// Print a lot more text running it on another location!
#[on("site_2")]
{
println("Multiple messages coming in!:");
for (let i := 0; i < 10; i := i + 1) {
print("Message "); print(i); print(": ");
println(hello_world());
}
}
Listing 1: Example BraneScript snippet showing how the language looks using a typical "Hello, world!" example.
At compile time, the statements are analysed by the compiler to derive the intended workflow graph. Such a graph matching Listing 1 can be found in Figure 1.
Figure 1: Workflow graph that can be extracted from Listing 1. It shows the initial task execution and then the repeated execution of the same function. In practise, this loop might be unrolled for simpler analysis, but this cannot always be done (e.g., conditional loops).
Main concepts
BraneScript leans on well-established concepts from other programming languages.
First, a BraneScript program is defined as a series of statements. These are the smallest units of coherent programs. Statements typically indicate control flow between expressions (see below), where particular constructs can be used for particular types of flow (e.g., if-statements, for-loops, while-loops, parallel-statements, etc). Like most scripting languages, they needn't be nested in a function (see below).
Actual work is performed in expressions, which can be thought of as imperative formulas creating, transforming and consuming values. Aside from literal values (booleans, integers, real numbers, strings), BraneScript also supports arrays of values (i.e., dynamically-sized containers of multiple of the same values) and classes (i.e., statically-sized containers of different values). Operations supported in expressions are logical operations (conjunction, disjunction), arithmetic operations (addition, subtraction, multiplication, division, modulo) and comparison operators. Operations like array indexing or function calls are also supported.
BraneScript also has a concept of variables, which can remember values across statements. Essentially, these are named segments of memory that can be assigned values that can later be read.
Functions can be used to make the codebase more efficient, or implement specific programming paradigms (such as recursion). Formally, functions can be thought of as "custom operations" in expressions. They might take in a value, define how to process that value and then potentially return a (new) one. Not all functions do this, though, and instead may produce side-effects by calling builtin- or package methods.
Note that classes can also be associated with functions to define class methods.
Finally, specific to BraneScript, external functions are imported as packages and treated like normal function within the scripting language. However, instead of executing BraneScript statements, these functions execute a workflow task dynamically on Brane infrastructure. Their result is translated back to BraneScript concepts.
Statements
This section lists the specific statements supported by BraneScript.
Expression statements
println("Hello, world!");
42 + 42;
55 + add(33, 44);
Expression statements represent the straightforward execution of a particular expression. The result of the expression is not stored (see below), and so it is typically used for function calls which do not return a value, or if we're not interested in the returned value.
(Let) Assignments
// Example assignment to new variables
let value := 42;
// Example assignment to existing variables
value := 42 * 2;
Let assignments are like expression statements, except that the value computed by the expression is stored in a variable.
There are two versions of this syntax: first, there is the let assignment, which can be used to declare a variable and immediately assign it a particular value. Then, once the variable has been declared, its value can be updated using a normal assignment.
If-statements
// This assigns either 42 or 82, depending on the value of `foo`
let foo := true;
let bar := null;
if (foo) {
bar := 42;
} else {
bar := 84;
}
// The variation that only defines a true-branch
let foo := true;
let bar := null;
if (foo) {
bar := 42;
}
If-statements represent a conditional divergence in control flow. It analyses a given expression that evaluates to a boolean, and executes one of two branches of statements: the top one if the value is true, or the bottom one if it's false.
A variation of this statement exists where the second branch may be omitted if it contains no statements.
While-loops
let counter := 0;
while (counter < 10) {
println("Hello, world!");
counter := counter + 1;
}
Sometimes, a series of statements needs to be repeated a conditional number of times. In these cases, a while-loop can be used; it repeats a series of statements as long as the given boolean expression evaluates to true.
For-loops
for (let i := 0; i < 10; i := i + 1) {
println("Hello, world!");
}
As syntax sugar for a while-loop, a for-loop also repeats a series of statements until a particular condition is reached. It is tailored more for iterations that are repeated a particular number of items instead of an arbitrary condition.
The syntax of the for-loop is as follows. The input to the loop is separated into three parts using semicolons: the first is executed before the loop; the second is used as the while-loop's condition; and the last part is executed at the end of every loop.
Note that, while the styling suggests a C-like syntax, it is not as freeform as that. Instead, only the name of the variable (i, in the example), the condition (i < 10) and the increment-expression (i + 1) can be changed.
Parallel statements
// Execute stuff in parallel!
parallel [{
println("Hello, world! 1");
}, {
println("Hello, world! 2");
}];
// Alternative form to return a value (and showing multiple branches are possible)
let result := parallel [all] [{
return 42;
}, {
return 84;
}, {
return 126;
}];
The parallel-statement is slightly more unique to BraneScript, and denotes that two series of statements can be executed in parallel. This is mostly useful when either contains external function calls, but in practise also launches the BraneScript statements concurrently.
There are two forms of the statement. In the first, work is just executed in parallel. In the second, a value may be returned from the branches (using a return-statement) that is aggregated somehow and placed in the variable preceding the statement. How the variables are aggregated is denoted by the merge strategy ([all] in the example).
Block statements
// We can nest statements in a block arbitrarily to play with scoping rules
let foo := 42;
println(foo); // 42
{
// Shadowed!
let foo := 84;
println(foo); // 84
}
println(foo); // 42
Typically, blocks of statements are used in function declarations, if-statements or other constructs. Essentially, they just group statements together visually. However, importantly, blocks also directly define scopes, i.e., they specify which variables are visible and thus usable for the programmer. When using a block as a separate statement, it is used to introduce an additional scope to shadow variables or free values early.
Function declarations
// A function without arguments
func hello_world() {
println("Hello, world!");
}
// A function _with_ arguments!
func add(lhs, rhs) {
return lhs + rhs;
}
Functions can be used to group statements under a particular name, which can then later be called. The function declarations define which statements are executed, and which arguments the function has as input. Syntactically, these are represented as variables scoped to the function and populated when a call is performed.
To return a value from the function to the calling scope, use return-statements.
Return statements
// Returns '42' from the workflow
return 42;
// Only interrupts the control flow, returns nothing
return;
To return values from functions, a return-statement may be used. When executed, it immediately interrupts the current body (either from a function or the main script body), and goes back to where that was called. When given with a value, that value subsequently gets set as the value of the function call. When used at the toplevel of the script, this means that returns terminate the whole script and potentially return a value back to the user. In parallel stements, they are used to terminate branches and return values for aggregation.
Import statements
// Import the latest available version of a package
import hello_world;
// Or a specific version
import hello_world[1.0.0];
Unique to BraneScript are import-statements, which are used to bring the external functions of packages into scope. They can either be given without version number, in which case the latest version is used, or with, in which case the given version is used.
Note that imports are always relative to the execution context, not the compile context.
Class declarations
// A class is a statically-sized, heterogenous container of multiple values
class Test {
value1: int;
value2: string;
// ...with functions that can act on it!
func print(self) {
print(self.value1);
print(" and '");
print(self.value2);
println("'");
}
}
Oftentimes, it is practical to group multiple values together. A BraneScript class is one way of doing so. Unlike arrays, classes can contain values of different types; but to do so, first they have to be statically defined so that the execution engine knows the shape of the class and how to access its contents.
To support OOP-like programming paradigms, BraneScript classes can also be annotated methods. These are functions that act on a particular instance of a class, and come accompanied with convenient syntax for using them. Note, however, that BraneScript misses a few features for using full OOP; for example, there is no way to define object inheritance.
Syntactically, the class is defined as a special kind of block that lists its contents (fields) as name/type pairs. A function can be given, which always takes self as first parameter, to define a method. Note that associated functions (i.e., functions without self) are not supported.
Attributes
#[on("foo")]
#[tag("amy.bar")]
#[something_else]
#![inner_annotation]
As a final BraneScript statement, attributes (sometimes called annotations) can be used to provide some additional metadata to the compiler. While syntactically, any identifier can be used, only a few are recognized by the compiler, having their own syntax for arguments.
Attributes in the form of #[...] always annotate the first non-attribute statement succeeding it. If this statement has nested statements (e.g., a block, if-statement, etc), then the attribute is propagated to all the nested statements as well. For example:
#[attribute]
{
// The if-statement is annotated with `attribute`
if (true) {
// And this expression-statement has `attribute` too
println("Hello, world!");
}
}
As an alternative syntax, the #![...]-form (not the exclaimation mark !) annotates every statement in the parent block. To illustrate:
// Same effect as the snippet above!
{
#![annotate]
// The if-statement is annotated with `attribute`
if (true) {
// And this expression-statement has `attribute` too
println("Hello, world!");
}
}
This latter form can be used to annotate an entire BraneScript file (e.g., wf-tag; see below).
The following attributes are currently recognized by the compiler:
on(<locs...>)ORloc(<locs...>)ORlocation(<locs...>): Explicitly states domains in a Brane instance where a particular external call must be executed. This can be used to implement Trusted Third-Parties, for example.tag(<tags...>)ORmetadata(<tags...>): Adds an arbitrary piece of metadata (a string) to external calls, which may be used by policy to learn information non-derivable from the call itself. An example of this would be GDPR-like purpose tags. Note that the tags must be given as<owner>.<tag>, where the owner is the domain or entity responsible for defining it.wf-tag(<tags...>)ORworkflow-tag(<tags...>)ORwf-metadata(<tags...>)ORworkflow-metadata(<tags...>): Adds an arbitrary piece of metadata (a string) to the workflow as a whole, which may be used by policy to learn information non-derivable from the call itself. An example of this would be GDPR-like purpose tags. Note that the tags must be given as<owner>.<tag>, where the owner is the domain or entity responsible for defining it.
Expressions
This section lists the particular operators and other constructs that can be used in BraneScript expressions.
Note that expressions are typically defined recursively, meaning that arbitrarily complex expressions can be built by nesting them (e.g., 42 + 42 - 42 nests the addition as a child of the subtraction).
Literals
42
"Amy"
84.0
true
1.0.0
null
The simplest expression possible is a literal, which evaluates to the value written down. For every primitive data type, there is an associated literal; these are booleans, integers, real numbers, strings, version triplets and null.
Variable access
foo
Instead of providing a literal value, a variable can also be referenced. In that case, it evaluates to the value that was assigned to it most recently, of the type associated with the variable (see the rules about typing).
Operators
42 + 42
4 * 8
"Hello, " + "world!"
!true
-42
-82.0
42 % 4 - 3
Operators can be used to manipulate the results of other expressions. Available operators can be separated into roughly two classes: unary operators, which take only a single expression; and binary operators, which manipulate two expressions, usually aggregating them somehow.
Note that operators are subject to precedence (i.e., which operator should be considered first) and associativity (i.e., in which order are the operators considered when all of the same type). These are discussed in the formal grammar chapter.
The following operators are available in BraneScript:
- Logical operators
- Negation (
!<bool expr>): "Flips" the boolean value (e.g., true becomes false and false becomes true). - Conjunction (
<bool expr> && <bool expr>): Takes the logical conjunction of the two values (i.e., returns true iff both expressions are true). - Disjunction (
<bool expr> || <bool expr>): Takes the logical disjunction of the two values (i.e., returns true iff at least one of both expressions is true).
- Negation (
- Arithmetic operators
- Addition (
<int expr> + <int exprOR<real expr> + <real expr>OR<str expr> + <str expr>): Adds two numerical values, or concatenates two strings. - Subtraction (
<int expr> - <int expr>OR<real expr> - <real expr>): Subtracts the second value from the first. - Multiplication (
<int expr> * <int expr>OR<real expr> * <real expr>): Multiplies two numerical values. - Division (
<int expr> / <int expr>OR<real expr> / <real expr>): Divides the first value by the second. The first case defines integer division, which is like normal division except that the answer is always rounded down to the nearest integer. - Modulo (
<int expr> % <int expr>): Returns the remainder after integer dividing the first value by the second.
- Addition (
- Comparison operators
- Equality (
<expr> == <expr>): Evaluates to true if the two values are the same (including of the same type), or false otherwise. - Inequality (
<expr> != <expr>): Evaluates to true if the two values are not the same (happens when they don't share the same type), or false otherwise. - Less than (
<int expr> < <int expr>OR<real expr> < <real expr>): Evaluates to true if the first value is strictly lower than the second value. - Less than or equal (
<int expr> <= <int expr>OR<real expr> <= <real expr>): Evaluates to true if the first value is lower than or equal to the second value. - Greater than (
<int expr> > <int expr>OR<real expr> > <real expr>): Evaluates to true if the first value is strictly higher than the second value. - Greater than or equal (
<int expr> >= <int expr>OR<real expr> >= <real expr>): Evaluates to true if the first value is higher than or equal to the second value.
- Equality (
Function calls
println("Hello, world!")
add(42, foo)
magic_number()
add(magic_number(), 42 / 2)
After a function has been defined, it can be called as an expression. It can be given arguments if the declarations declares them, which are nested expressions that should evaluate to the type required by that function.
After the call completes, the function call evaluates to the value returned by the function. Functions returning nothing (i.e., Void) will always cause type errors when their value is used, so only use that as a "terminating" expression (i.e., one that is not nested in another expression and who's value is not used).
Note that calls to external functions (i.e., those imported) use the exact same syntax as regular function calls.
Arrays
[]
[1, 2, 3, 4]
[magic_numer(), 42 + 4, 88]
As an alternative to classes, arrays are part of BraneScript as ad-hoc containers for values of a shared type. In particular, and array can be thought of as a continious block of data of variable length.
Arrays can be constructed using Python-like syntax, after which they will evaluate to an array of the type of its elements. As it is an expression, it can be stored in variables and used for later.
Array indexing
foo[0]
[1, 2, 3][5]
generates_array()[4 - bar]
To access the contents of an array instead of the array as a whole, an index expression can be used. This takes in an expression evaluating to an array first, and then some (zero-indexed!) index into that array. The index expression as a whole evaluates to the selected element.
Note that using an index that is the same or higher than the length of the array will cause runtime errors.
Class instantiation
new Test { value1 := 42, value2 := "Hello, world!" };
new Jedi {
name := "Obi-Wan Kenobi",
is_master := true,
lightsaber_colour := "blue"
}
new Data { name := "test" }
After a class has been declared, it can be instantiated, meaning that we create the container with appropriate values. The syntax used writes the fields as if they were assignments, taking the name before the := and an expression evaluating to that field's type after it.
Projection
test.value1
jedi.is_master
big_instance.small_instance.value
Once a class has been instantiated, its individual values may be accessed using projection. This selects a particular field in the given class instance, and evaluates to the most recently assigned value to that field.
The syntax is first an expression evaluating to an instance (including other projections!), and then an identifier with the field name.
Note that projections are special in that they may also appear to the left of a regular assignments, e.g.,
test.value1 := 84;
may be used to update the values of fields in instances.
Next
This defines the basic statements and expressions in BraneScript, and can already be used to write simple programs. Refer to the user guide to find more information about how to do so.
This documentation continues by going in-depth on some other parts of the language. In particular, subsequent chapters will deal with the formal grammar of the language; scoping rules; typing rules; workflow analysis; and other compilation steps. The final chapter in this series concludes with future work planned for BraneScript.
If you're no longer interested in BraneScript, you can alternatively read another topic in the sidebar on the left.
Formal grammar
In this chapter, we present the formal grammar of Brane in Backus-Naur form (or something very much like it). This will show you what's possible to write in BraneScript and how the language is structured.
This chapter is very technical, and mostly suited for implementing a BraneScript parser. To find out more details about compiling BraneScript to the Workflow Intermediate Representation (WIR), consult the next chapters.
Conventions
As already stated, we will be using something like the Backus-Naur form in order to express the grammar (using the syntax as given on Wikipedia). However, we use certain conventions to structure the discussion.
First, BraneScript parsing is done in two-steps: first, a scanning or tokenization step, and then a parsing step of those tokens. We do the same here, where we will indicate tokens (i.e., terminals) in ALL CAPS. Non-terminals, which are parsed from the tokens, are indicated by CamelCaps.
Note that the order of tokens matters in that, in the case of ambiguity of parsing tokens, then tokens appearing first should be attempted first.
Then, we define an additional type of expression: regular expressions. These are given like literals ("..."), except that they are prefixed by an r (e.g., r"..."). If so, then the contents of the string should be understood as TextMate regular expressions.
Note that the grammar does not encode operator precedence and associativity. Instead, this is defined separately below.
Finally, we also use our own notion of comments, prefixed by a double slash (//). Anything from (and including) the double slash until the end of the line (or file) can be ignored for the official grammar.
Grammar
Now follows the grammar of BraneScript.
///// NON-TERMINALS /////
// Statements
Stmts ::= Stmts Stmt
| Stmt
Stmt ::= Attribute | AttributeInner | Assign | Block | ClassDecl | ExprStmt | For | FuncDecl
| If | Import | LetAssign | Parallel | Return | While
Attribute ::= POUND LBRACKET AttrKeyPair RBRACKET
| POUND LBRACKET AttrList RBRACKET
AttributeInner ::= POUND NOT LBRACKET AttrKeyPair RBRACKET
| POUND NOT LBRACKET AttrList RBRACKET
AttrKeyPair ::= IDENT EQUAL Literal
AttrList ::= IDENT LPAREN Literals RPAREN
Literals ::= Literals Literal
| Literal
Assign ::= IDENT ASSIGN Expr SEMICOLON
Block ::= LBRACE Stmts RBRACE
| LBRACE RBRACE
ClassDecl ::= CLASS IDENT LBRACE ClassStmts RBRACE
ClassStmts ::= ClassStmts Prop
| ClassStmts FuncDecl
| Prop
| FuncDecl
Prop ::= IDENT COLON IDENT SEMICOLON
ExprStmt ::= Expr SEMICOLON
For ::= FOR LPAREN LetAssign Expr SEMICOLON IDENT ASSIGN Expr RPAREN Block
FuncDecl ::= FUNCTION IDENT LPAREN Args RPAREN Block
| FUNCTION IDENT LPAREN RPAREN Block
Args ::= Args COMMA IDENT
| IDENT
If ::= IF LPAREN Expr RPAREN Block
| IF LPAREN Expr RPAREN Block ELSE Block
Import ::= IMPORT IDENT SEMICOLON
| IMPORT IDENT LBRACKET SEMVER RBRACKET SEMICOLON
LetAssign ::= LET IDENT ASSIGN Expr SEMICOLON
Parallel ::= PARALLEL LBRACKET PBlocks RBRACKET SEMICOLON
| PARALLEL LBRACKET IDENT RBRACKET LBRACKET PBlocks RBRACKET SEMICOLON
| LET IDENT ASSIGN PARALLEL LBRACKET PBlocks RBRACKET SEMICOLON
| LET IDENT ASSIGN PARALLEL LBRACKET IDENT RBRACKET LBRACKET PBlocks RBRACKET SEMICOLON
PBlocks ::= PBlocks COMMA Block
| Block
Return ::= RETURN Expr SEMICOLON
| RETURN SEMICOLON
While ::= WHILE LPAREN Expr RPAREN Block
// Expressions
Exprs ::= Exprs COMMA Expr
| Expr
Expr ::= LPAREN Expr RPAREN
| Expr BinOp Expr
| UnaOp Expr
| Array | ArrayIndex | Call | IDENT | Instance | Literal
| Projection
BinOp ::= AND AND | EQUAL | GREATER | GREATEREQ | LESS | LESSEQ | MINUS | NOTEQ
| OR OR | PERCENTAGE | PLUS | SLASH | STAR
UnaOp ::= NOT | MINUS
Array ::= LBRACKET Exprs RBRACKET
| LBRACKET RBRACKET
ArrayIndex ::= Array LBRACKET Expr RBRACKET
Call ::= IDENT LPAREN Exprs RPAREN
| Projection LPAREN Exprs RPAREN
| IDENT LPAREN RPAREN
| Projection LPAREN RPAREN
Instance ::= NEW IDENT LBRACE InstanceProps RBRACE
| NEW IDENT LBRACE RBRACE
InstanceProps ::= InstanceProps COMMA InstanceProp
| InstanceProp
InstanceProp ::= IDENT ASSIGN Expr
Literal ::= BOOLEAN | INTEGER | NULL | REAL | STRING
Projection ::= Projection DOT IDENT
| IDENT DOT IDENT
///// TERMINALS /////
// Keywords (and other tokens needing to be parsed first)
ASSIGN ::= ":="
BREAK ::= "break"
CLASS ::= "class"
CONTINUE ::= "continue"
ELSE ::= "else"
FOR ::= "for"
FUNCTION ::= "func"
GREATEREQ ::= ">="
IF ::= "if"
IMPORT ::= "import"
LESSEQ ::= "<="
LET ::= "let"
NEW ::= "new"
NOTEQ ::= "!="
NULL ::= "null"
ON ::= "on"
PARALLEL ::= "parallel"
RETURN ::= "return"
WHILE ::= "while"
// Punctuation
AND ::= "&"
AT ::= "@"
LBRACE ::= "{"
RBRACE ::= "}"
LBRACKET ::= "["
RBRACKET ::= "}"
COLON ::= ":"
COMMA ::= ","
DOT ::= "."
EQUAL ::= "="
GREATER ::= ">"
LESS ::= "<"
MINUS ::= "-"
NOT ::= "!"
OR ::= "|"
LPAREN ::= "("
RPAREN ::= ")"
PERCENTAGE ::= "%"
PLUS ::= "+"
POUND ::= "#"
SEMICOLON ::= ";"
SLASH ::= "/"
STAR ::= "*"
// Tokens with values
SEMVER ::= r"[0-9]+\.[0-9]+\.[0-9]+" // 1
REAL ::= r"([0-9_])*\.([0-9_])+([eE][+\-]?([0-9_])+)?" // 2
BOOLEAN ::= r"(true|false)"
IDENT ::= r"[a-zA-Z_][a-zA-Z_0-9]*" // 3
INTEGER ::= r"([0-9_])+"
STRING ::= r"\"([^\"\\]|\\[\"'ntr\\])*\""
///// REMARKS /////
// 1: Has to be before REAL & INTEGER
// 2: Has to be before INTEGER
// 3: Has to be below BOOLEAN & keywords
Operator precedence & associativity
The grammar above does not encode precedence and associativity for brevity purposes. Instead, they are given here in Table 1.
| Operator | Precedence | Associativity |
|---|---|---|
| && | 0 | Left |
| || | 0 | Left |
| == | 1 | Left |
| != | 1 | Left |
| < | 2 | Left |
| > | 2 | Left |
| <= | 2 | Left |
| >= | 2 | Left |
| + | 3 | Left |
| - | 3 | Left |
| * | 4 | Left |
| / | 4 | Left |
| % | 4 | Left |
| ! | 5 | Unary |
| - | 5 | Unary |
Table 1: Operator precedence and associativity for BraneScript. An operator with a higher precedence will bind stronger, and an operator with left-associativity will create parenthesis on the left.
Next
The compilation of BraneScript to the WIR, and thus details about how to interpret the AST obtained by parsing BraneScript, are discussed in the next chapter.
Alternatively, if you want to know what BraneScript can be instead of what it is, refer to the Future work-chapter.
Scoping rules
In this chapter, we will detail BraneScript's scoping rules and how variables are bound to their declaration. This matches the procedure followed in the resolve compiler traversal.
It is recommended to read the Features-chapter first to have an overview of the language as a whole before diving into the specifics.
Variables VS functions
TODO
Scoping - why we care
At the start of every workflow compilation, there is a compiler traversal (the resolve-traversal) that attempts to link variables references (e.g., foo) to variable declarations (e.g., let foo := ...). You can think of this step as relating identifiers with each other, creating symbol tables to keep track of which variables are introduced and where they are set and read.
For example:
// This tells the compiler we define a new variable
let foo := 42;
// Knowing that, it can relate this `foo` to that `foo`
println(foo);
// Uh-oh! We are using some `bar` we've never seen before, and therefore cannot relate!
println(bar);
As this process is done using name-matching, one may note that this strategy normally means we would muddy our namespace quite quickly. For example, what if we want to introduce a temporary variable; if there was only one scope, it would be around forever; e.g.,
// We only need this here
let foo := 42;
println(foo);
...
// Much later, we want to name something foo again - but confusion strikes, as it's
// not obvious if we mean this foo or the previous one!
let foo := 84;
As a solution to this problem, we create scopes to help the compiler identify which variable is meant when they share the same name.
The magic brackets
As a rule of thumb, a new scope is introduced for every opening curly bracket {, and closed on every closing curly bracket }. For example:
// The global scope
{
// A nested scope!
}
if (true) {
// A scope for the true-branch, nested in `global`
} else {
// A scope for the false-branch, nested in `global` too
}
func foo() {
// A scope for only this function!
{
// This scope is nested in `global` and then `foo`
}
}
A variable declared in a particular scope (e.g., let foo := ...) is known only in that scope, and all its nested scopes. For example:
// Known everywhere, as it is defined in the "root" scope
let foo := 42;
{
println(foo); // works
if (true) {
println(foo); // works
}
}
println(foo); // works
{
// Only known in this scope and below
let foo := 42;
println(foo); // works
if (true) {
println(foo); // works
}
}
println(foo); // does not work!
Shadowing variables
One particular usage of a scope is to shadow variables; i.e., we can "override" an identifier to be used for a variable in a lower scope, while the same variable is used in a higher scope. For example:
let foo := 42;
println(foo); // 42
{
// This `foo` shadows the top one; same name, but actually a new variable!
let foo := 84;
println(foo); // 84
}
println(foo); // 42 again!
In fact, BraneScript also allows shadowing in the same scope. This only means that the old variable may never be referenced again:
let foo := 42;
println(foo); // 42
// This declares a _new_ variable
let foo := "Hello, world!";
println(foo); // Hello, world!
// There is just no way for us now to refer to the first variable
This may raise the question as to why BraneScript even has scopes, as the main motivating reason was to help the compiler disambiguate variables with the same name, but it turns out we can do that without even needing them. For that, see the future work-chapter.
Assignment scoping
There is a second scoping rule that is used to resolve variables. Suppose that we want to store an old foo into a new foo:
let foo := 42;
// May seem redundant, but we would expect it to work!
let foo := foo + 1;
However, now the compiler may be led into ambiguity, as the two foos appear in the same statement. So which foo refers to which?
To resolve, the assignment operator := also introduces a kind of change in scope. In particular, anything to the right of the scope is evaluated first using the old scope. Then, the foo on the left is created, virtually creating a new scope that holds from that point onwards.
Function body scoping
Functions have a few particular rules about them when discussing scoping.
First, the scope of a function body is not nested in the parent scope. For example:
// Refresher; this works usually
let foo := 42;
println(foo);
// But this doesn't, as the function has no access to the parent scope
func bar() {
println(foo); // 'Undeclared variable' error
}
This is a design decision made for BraneScript, which simplifies the resolve process when submitting a workflow as successive snippets (see the background).
Instead, values can be passed to functions through parameters:
let foo := 42;
func bar(foo) {
println(foo);
}
// Call, then:
bar(foo);
Where parameters are always declared in the scope of the function.
Class scoping
TODO
Typing rules
Workflow analysis
Compilation
While-loops (and For-loops)
We come from the following internal AST representation of a for-loop:
#![allow(unused)] fn main() { enum Stmt { While { /// The expression that has to evaluate to true while running. condition : Expr, /// The block to run every iteration. consequent : Box<Block>, // ... }, // ... } }
We want to convert that to a series of graphs and edges. This is done as follows:
- Compile the condition to a series of edges computing the condition (this ends in an
EdgeBufferNodeLink::Endif the expression does not fully return); - Compile the consequent to a series of edges (this ends in an [
EdgeBufferNodeLink::End] if the statements do not fully return); - Write it as a Loop connector, with the ends of the condition and consequent still
Ends - [In
workflow_resolve.rs] Write the condition to a separate series of edges with resolved indices. - [In
workflow_resolve.rs] Write the consequence to a separate series of edges with resolved indices. - [In
workflow_resolve.rs] Write the condition as a branch to the loop-global buffer, with the true-branch being the condition, the false branch being the edges after the loop. - [In
workflow_resolve.rs] Write the consequence to the loop-global buffer directly after the condition. - [In
workflow_resolve.rs] Write the loop node, then the loop-global buffers.
So, in conclusion: the result is a Loop-edge, pointing to a series of edges that computes the condition, then a branch that does the body or skips over it. The loop-edge then contains pointers into this buffer, even though the loop itself is quite serialized already.
Future work
Destructors
Rust-like expressions
Parallel statements, blocks
Merging Data and IntermediateResult
Workflow parameters
Data types
Deeper data integration?